Last time we met we spoke of my fellow students' and my interest in constructing a model of the motion of heavenly bodies using mathematical formulae in the place of brass. In particular we have sought to do so from first principals using Sir N-----'s law of universal gravitation, which states that the force attracting two bodies is proportional to the product of their masses divided by the square of the distance between them, and his laws of motion, which state that a body will remain at rest or in constant motion unless a force acts upon it, that it will be accelerated in the direction of that force at a rate proportional to its magnitude divided the body's mass and that a force acting upon it will be met with an equal force in the opposite direction.
Whilst Sir N----- showed that a pair of bodies traversed conic sections under gravity, being those curves that arise from the intersection of planes with cones, the general case of several bodies has proved utterly resistant to mathematical reckoning. We must therefore approximate the equations of motion and I shall now report on our first attempt at doing so.
I was at the Zero-Knowledge proofs workshop run by BinaryDistict on Monday and Tuesday. The workshop runs all week, but is mostly hacking for the remaining days (hacking would be interesting if I had a problem to code, more about this at the end).
Zero-knowledge proofs allow person A to convince person B, that A knows the value of x, without revealing the value of x. There are two kinds of zero-knowledge proofs: an interacting proof system involves a sequence of messages being exchanged between the two parties, and in non-interactive systems (the primary focus of the workshop), there is no interaction.
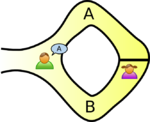
The example usually given, of a zero-knowledge proof, involves Peggy and Victor. Peggy wants to convince Victor that she knows how to unlock the door dividing a looping path through a tunnel in a cave.
The ‘proof’ involves Peggy walking, unseen by Victor, down path A or B (see diagram below; image from Wikipedia). Once Peggy is out of view, Victor randomly shouts out A or B; Peggy then has to walk out of the tunnel using the path Victor shouted; there is a 50% chance that Peggy happened to choose the path selected by Victor. The proof is iterative; at the end of each iteration, Victor’s uncertainty of Peggy’s claim of being able to open the door is reduced by 50%. Victor has to iterate until he is sufficiently satisfied that Peggy knows how to open the door.
As the name suggests, non-interactive proofs do not involve any message passing; in the common reference string model, a string of symbols, generated by person making the claim of knowledge, is encoded in such a way that it can be used by third-parties to verify the claim of knowledge. At the workshop we got an overview of zk-SNARKs (zero-knowledge succinct non-interactive argument of knowledge).
The ‘succinct’ component of zk-SNARK is what has made this approach practical. When non-interactive proofs were first proposed, the arguments of knowledge contained around one-terabyte of data; these days common reference strings are around a kilobyte.
The fact that zero-knowledge ‘proof’s are possible is very interesting, but do they have practical uses?
The hackathon aspect of the workshop was designed to address the practical use issue. The existing zero-knowledge proofs tend to involve the use of prime numbers, or the factors of very large numbers (as might be expected of a proof system that was heavily based on cryptography). Making use of zero-knowledge proofs requires mapping the problem to a form that has a known solution; this is very hard. Existing applications involve cryptography and block-chains (Zcash is a cryptocurrency that has an option that provides privacy via zero-knowledge proofs), both heavy users of number theory.
The workshop introduced us to two languages, which could be used for writing zero-knowledge applications; ZoKrates and snarky. The weekend before the workshop, I tried to install both languages: ZoKrates installed quickly and painlessly, while I could not get snarky installed (I was old that the first two hours of the snarky workshop were spent getting installs to work); I also noticed that ZoKrates had greater presence than snarky on the web, in the form of pages discussing the language. It seemed to me that ZoKrates was the market leader. The workshop presenters included people involved with both languages; Jacob Eberhardt (one of the people behind ZoKrates) gave a great presentation, and had good slides. Team ZoKrates is clearly the one to watch.
As an experienced hack attendee, I was ready with an interesting problem to solve. After I explained the problem to those opting to use ZoKrates, somebody suggested that oblivious transfer could be used to solve my problem (and indeed, 1-out-of-n oblivious transfer does offer the required functionality).
My problem was: Let’s say I have three software products, the customer has a copy of all three products, and is willing to pay the license fee to use one of these products. However, the customer does not want me to know which of the three products they are using. How can I send them a product specific license key, without knowing which product they are going to use? Oblivious transfer involves a sequence of message exchanges (each exchange involves three messages, one for each product) with the final exchange requiring that I send three messages, each containing a separate product key (one for each product); the customer can only successfully decode the product-specific message they had selected earlier in the process (decoding the other two messages produces random characters, i.e., no product key).
Like most hackathons, problem ideas were somewhat contrived (a few people wanted to delve further into the technical details). I could not find an interesting team to join, and left them to it for the rest of the week.
There were 50-60 people on the first day, and 30-40 on the second. Many of the people I spoke to were recent graduates, and half of the speakers were doing or had just completed PhDs; the field is completely new. If zero-knowledge proofs take off, decisions made over the next year or two by the people at this workshop will impact the path the field follows. Otherwise, nothing happens, and a bunch of people will have interesting memories about stuff they dabbled in, when young.
The thing we call Agile is a virus. It gets into organizations and disrupts the normal course of business. In the early days, say before 2010, the corporate anti-bodies could be counted on to root out and destroy the virus before too much damage was done.
But sometimes the anti-bodies didn’t work. As the old maxim says “that which doesn’t kill me makes me stronger.†Sometimes agile made the organization stronger. Software development teams produced more stuff, they delivered on schedule, employees were happier, they had fewer bugs. In smaller, less established companies, the virus infected the company central nervous system, the operating system, and subverted it. Agile became natural.
The problem is, once the virus is inside the organization/organism it wants to grow and expand. It you don’t kill it then it will infect more and more of the body. Hence, software teams that contracted the agile virus and found it beneficial were allowed to survive but at the same time the virus spread downstream to the requirements process. Business Analysts and Product Managers had to become agile too.
Once you are infected you start to see the world through infected eyes. Over time the project model looked increasingly counter productive. Growth of the agile virus lead to the #NoProjects movement as the virus started to change management models.
Similar things are happening in the accounting and budgeting field. As the agile virus takes hold, and especially once the #NoProjects mutation kicks in, the annual budget process looks crazy. Agile creates a force for more change, agile demands Beyond Budgetting. Sure you can do agile in a traditional budget environment but the more you do the more contradictions you see and the more problems you encounter.
Then there is “human resources†– or to give it a more humane name personnel. Traditional staff recruitment, line management, individual bonuses and retention polices start to look wrong when you are infected by agile. Forces grow to change things, the more the organization resists the virus the more those infected by the virus grow discontent and the more unbalanced things become.
It carries on. The more successful agile is the greater the forces pressing for more change.
While companies don’t recognise these forces they grow. Hierarchical organizations and cultures (like banks) have this really bad. At the highest level they have come to recognise the advantages of the agile virus but to embrace it entirely is to destroy the essence of the organization.
Countless companies try to contain the agile virus but to do so they need to exert more and more energy. Really they need to kill it or embrace it and accept the mutation that is the virus.
Ultimately it all comes down to forces. The forces of status quo and traditional working (Theory X) on one side against the forces of twenty-first century digital enabled millennial workforce (Theory Y) on the other. Victory for the virus is inevitable but that does not mean every organization will be victorious or even survive. Those who can harness the virus fastest stand to gain the most.
The virus has been released, putting the genie back in the bottle is going to be hard – although the paradox of digital technology is that while the digital elite stand to gain the digital underclass (think Amazon warehouse workers) stand to lose.
All companies need to try to embrace the virus, to not do so would be to condemn oneself. But not all will succeed, in fact most will fail trying. Their failures will allow space for new comers to succeed, that is the beauty of capitalism. Unfortunately that space might be also be grabbed by the winners, the companies that have let the virus take over the organization.
Like this post? – Like to receive these posts by e-mail?
The so called Lehman laws of software evolution originated in a 1968 study, and evolved during the 1970s; the book “Program Evolution: processes of software change” by Lehman and Belady was published in 1985.
The original work was based on measurements of OS/360, IBM’s flagship operating system for the computer industries flagship computer. IBM dominated the computer industry from the 1950s, through to the early 1980s; OS/360 was the Microsoft Windows, Android, and iOS of its day (in fact, it had more developer mind share than any of these operating systems).
In its day, the Lehman dataset not only bathed in reflected OS/360 developer mind-share, it was the only public dataset of its kind. But today, this dataset wouldn’t get a second look. Why? Because it contains just 19 measurement points, specifying: release date, number of modules, fraction of modules changed since the last release, number of statements, and number of components (I’m guessing these are high level programs or interfaces). Some of the OS/360 data is plotted in graphs appearing in early papers, and can be extracted; some of the graphs contain 18, rather than 19, points, and some of the values are not consistent between plots (extracted data); in later papers Lehman does point out that no statistical analysis of the data appears in his work (the purpose of the plots appears to be decorative, some papers don’t contain them).
Lehman’s ‘laws’ started out as a handful of observations about one very large software development project. Over time ‘laws’ have been added, deleted and modified; the Wikipedia page lists the ‘laws’ from the 1997 paper, Lehman retired from research in 2002.
The Lehman ‘laws’ of software evolution are still widely cited by academic researchers, almost 50-years later. Why is this? The two main reasons are: the ‘laws’ are sufficiently vague that it’s difficult to prove them wrong, and Lehman made a large investment in marketing these ‘laws (e.g., publishing lots of papers discussing these ‘laws’, and supervising PhD students who researched software evolution).
The Lehman ‘laws’ are not useful, in the sense that they cannot be used to make predictions; they apply to large systems that grow steadily (i.e., the kind of systems originally studied), and so don’t apply to some systems, that are completely rewritten. These ‘laws’ are really an indication that software engineering research has been in a state of limbo for many decades.
This is a recommended maintenance update for Visual Lint 7.0. The following changes are included:
System include folder and for loop compliance settings can now be read from Visual Studio 2019 project files which use the v142 toolset.
Device specific includes (e.g. "<ProjectFolder>/RTE/Device/TLE9879QXA40") are now read when loading Keil uVision 5 projects.
Updated the value of _MSC_FULL_VER in the PC-lint Plus compiler indirect files for Microsoft Visual Studio 6.0, 2008, 2010, 2012, 2013, 2015, 2017 and 2019 to reflect the version of the most recent update of the compiler shipped with each. Also enabled C++ 17 support (-std=c++17) with Visual Studio 2017 (VS2017 update 9.4 is C++ 17 complete) and Visual Studio 2019.
Removed an erroneous directive from the PC-lint Plus library indirect file rb-win32-pclint10.lnt (an implementation file invoked by lib-rb-win32.lnt).
Fixed a bug in the Analysis Tool Options Page which could prevent the "Browse for installation folder" button from working correctly.
Fixed a bug in the Project Properties Dialog which affected the editing of configurations within custom projects.
Fixed a bug in the VisualLintGui Products Display "Remove File" context menu command.
The Configuration Wizard "Select Analysis Tool Installation Folder" page no longer indicates that you can buy PC-lint licences from Riverblade as this analysis tool has now been superseded by PC-lint Plus.
VisualLintGui now displays the correct page title when loading the "Blog" page on the Riverblade website.
Fixed a typo in the "Product Not Configured" dialog.
This is a recommended maintenance update for Visual Lint 7.0. The following changes are included:
System include folder and for loop compliance settings can now be read from Visual Studio 2019 project files which use the v142 toolset.
Device specific includes (e.g. "<ProjectFolder>/RTE/Device/TLE9879QXA40") are now read when loading Keil uVision 5 projects.
Updated the value of _MSC_FULL_VER in the PC-lint Plus compiler indirect files for Microsoft Visual Studio 6.0, 2008, 2010, 2012, 2013, 2015, 2017 and 2019 to reflect the version of the most recent update of the compiler shipped with each. Also enabled C++ 17 support (-std=c++17) with Visual Studio 2017 (VS2017 update 9.4 is C++ 17 complete) and Visual Studio 2019.
Removed an erroneous directive from the PC-lint Plus library indirect file rb-win32-pclint10.lnt (an implementation file invoked by lib-rb-win32.lnt).
Fixed a bug in the Analysis Tool Options Page which could prevent the "Browse for installation folder" button from working correctly.
Fixed a bug in the Project Properties Dialog which affected the editing of configurations within custom projects.
Fixed a bug in the VisualLintGui Products Display "Remove File" context menu command.
The Configuration Wizard "Select Analysis Tool Installation Folder" page no longer indicates that you can buy PC-lint licences from Riverblade as this analysis tool has now been superseded by PC-lint Plus.
VisualLintGui now displays the correct page title when loading the "Blog" page on the Riverblade website.
Fixed a typo in the "Product Not Configured" dialog.
The letters PCTE (Portable Common Tool Environment) might stir vague memories, for some readers. Don’t bother checking Wikipedia, there is no article covering this PCTE (although it is listed on the PCTE acronym page).
The ISO/IEC Standard 13719 Information technology — Portable common tool environment (PCTE) —, along with its three parts, has reached its 5-yearly renewal time.
The PCTE standard, in itself, is not interesting; as far as I know it was dead on arrival. What is interesting is the mindset, from a bygone era, that thought such a standard was a good idea; and, the continuing survival of a dead on arrival standard sheds an interesting light on ISO standards in the 21st century.
PCTE came out of the European Union’s first ESPRIT project, which ran from 1984 to 1989. Dedicated workstations for software developers were all the rage (no, not those toy microprocessor-based thingies, but big beefy machines with 15inch displays, and over a megabyte of memory), and computer-aided software engineering (CASE) tools were going to provide a huge productivity boost.
PCTE is a specification for a tool interface, i.e., an interface whereby competing CASE tools could provide data interoperability. The promise of CASE tools never materialized, and they faded away, removing the need for an interface standard.
CASE tools and PCTE are from an era where lots of managers still thought that factory production methods could be applied to software development.
PCTE was a European funded project coordinated by a (at the time) mainframe manufacturer. Big is beautiful, and specifications with clout are ISO standards (ECMA was used to fast track the document).
At the time Ada was the language that everybody was going to be writing in the future; so, of course, there is an Ada binding (there is also a C one, cannot ignore reality too much).
Why is there still an ISO standard for PCTE? All standards are reviewed every 5-years, countries have to vote to keep them, or not, or abstain. How has this standard managed to ‘live’ so long?
One explanation is that by being dead on arrival, PCTE never got the chance to annoy anybody, and nobody got to know anything about it. Standard’s committees tend to be content to leave things as they are; it would be impolite to vote to remove a document from the list of approved standards, without knowing anything about the subject area covered.
The members of IST/5, the British Standards committee responsible (yes, it falls within programming languages), know they know nothing about PCTE (and that its usage is likely to be rare to non-existent) could vote ABSTAIN. However, some member countries of SC22 might vote YES, because while they know they know nothing about PCTE, they probably know nothing about most of the documents, and a YES vote does not require any explanation (no, I am not suggesting some countries have joined SC22 to create a reason for flunkies to spend government money on international travel).
Prior to the Internet, ISO standards were only available in printed form. National standards bodies were required to hold printed copies of ISO standards, ready for when an order to arrive. When a standard having zero sales in the last 5-years, came up for review a pleasant person might show up at the IST/5 meeting (or have a quiet word with the chairman beforehand); did we really want to vote to keep this document as a standard? Just think of the shelf space (I never heard them mention the children dead trees). Now they have pdfs occupying rotating rust.
We have so far seen a couple of schemes for identifying clusters in sets of data which are subsets whose members are in some sense similar to each other. Specifically, we have looked at the k means and the shared near neighbours algorithms which implicitly define clusters by the closeness of each datum to the average of each cluster and by their closeness to each other respectively.
Note that both of these algorithms use a heuristic, or rule of thumb, to assign data to clusters, but there's another way to construct clusterings; define a heuristic to measure how close to each other a pair of clusters are and then, starting with each datum in a cluster of its own, progressively merge the closest pairs until we end up with a single cluster containing all of the data. This means that we'll end up with a sequence of clusterings and so before we can look at such algorithms we'll need a structure to represent them.
Officer: Well why don’t you move into more conventional areas of confectionery, … I mean look at this one, ‘cockroach cluster’, ‘anthrax ripple’. What’s this one, ‘spring surprise’?
Shop keeper: Ah – now, that’s our speciality – covered with darkest creamy chocolate. When you pop it in your mouth steel bolts spring out and plunge straight through-both cheeks.
That like Agile to me. In AgileLand everything is sweetness and light. Agile has all the answers. Everything works. Agile is utopia.
I’ve taught enough Agile Introduction courses to know this is so – and pushed ti too. There is no scenario I can’t fix in the classroom with the application of the right Agile principles, tool or mindset. And if I can’t… well in that case, Agile is helping you see the problem more clearly and you have to find your own solution.
Honestly, part of the appeal of Agile is that: Agile is a damn good story. Agile paints the picture of a better world, and so it should. Particularly when delivering an Agile training course I see my role as two fold:
In-part enough information so that teams can actually try Agile
Energise people to want to try it this way
Except, there are some dirty little secrets in the Agile world which do’t fit with this picture.
First up is Micromanagement (#1).
As I said in Devs Hate Agile, the Agile toolkit can be used for good or evil. If someone wants to be a micro-manager par-excellence then Agile – and particularly Scrum – make a great toolkit for micro-management too.
The intention behind the Agile/Scrum approach is to give those who do the work the tools and approaches to take control of their own work. When they do so then great things happen – the workers control the means of production! However those same tools can be used by very effectively by those who would control the workers.
What micromanager would not want every team member standing up to justify themselves at 9am each morning? Surely a micromanager would want working software at every opportunity? – and if you fail to deliver working software then…
In part this is because Agile is a great tool for apportioning blame (#2). When builds fail you know who did the last check-in. when tests fail you know who broke it, when cards don’t move on a board, sorry I mean Jira, then the powerful can hone in on those not pulling their weight.
Kanban is even better than Scrum here. I remember one Project Manager who used the Kanban board (26 columns!) we constructed to demonstrate why everybody apart from him was slowing work down. Try as I might I couldn’t get him to see each of problem to be worked on. To be fair to him, he was the product of a system where almost every step was undertaken by a sub-contractor, he had no power to change or reward sub-contractors, only to whip them.
Both these points illustrate the second dirty little secret: you don’t need to do everything (#3).
Simply holding stand-up meetings and end-of-iteration activities is a massive improvement for some teams.
Developers who adopt Test Driven Development will produce fewer bugs, waste less time in the debugger, and the testers who come after them will spend less time reporting bugs. Thus fewer bugs will need fixing and schedules will improve.
A Kanban board with WIP limits will improve workflow even if you do nothing else.
Yes, if you do every part of Scrum things will get a lot better.
And if you do every part of XP the total benefit will be better than the sum of the parts.
Part of the genius of Agile is that it can be implemented piecemeal. But that also means organizations and teams can stop. I’ve seen this a number of time: I introduce a bit of Agile, the immediate pain is relieved and the company looses the will to go further and improve more.
After all, who am I but an external consultant to tell them they could do better?
Once the pain if gone then the need to change goes too.
Now some dirty little secrets are being exposed. Most readers will know I have been active in exposing the dirty secret of Agile Project Management: the idea that Agile and the project model (aka project management) can work together.
Sure they can work together but… why? what is the point? Why go to the trouble of integrating Agile and Project Management?
Once you start working Agile the project model looks absurd. Hence #NoProjects – and why so many people have arrived at the same conclusion about projects independently.
In fact, it goes further than that. Companies that introduce full blown Scrum – including self-organizing teams – risk destroying themselves. In traditional, top-down, hierarchical companies Agile and self-organizing teams must be contained otherwise it will destroy the whole hierarchy. That is why banks struggle with Agile, the chocolate on the outside is really nice but sooner or later what they are eating runs up against what they are.
Finally, you might notice that in this post – and indeed in many of my other post – I don’t agree with other Agile advocates. Go and read Jeff Sutherland (I don’t agree over self-organization), Mike Cohn (I don’t agree over stories and points), Keith Richards (not the rolling stone, the APM man, I don’t agree over projects), Jim Coplien (he doesn’t agree over TDD), Joanna Rothman (we don’t agree on stories), Dan North (we don’t agree on teams) and just about anyone else and you’ll find I don’t agree 100% with anyone.
But the thing is: none of these people agree with each other.
Everyone in the Agile communities interprets it slightly differently.
The final dirty secret of Agile is: the experts don’t agree – there is no one true way (#5).
I feel sorry for new comers to Agile who expect to read the one-true-way but I’m also saw none of us “gurus†would want to any other way because we want variety and experimentation. And perhaps that is why one-size-fits all Agile scaling is always doomed.
Frog image credit: Argentine Horned Frog by Grosscha on WikiMediaCommons under CCL ASA 4.0 license
Like this post? – Like to receive these posts by e-mail?


1.JPG){kind=link}