Derek Jones from The Shape of Code
The Linux Counter project was started in 1993, with the aim of tracking the growth of Linux users (the kernel was first released two years earlier). Anybody could register any of their machines running Linux; a user ran a script that gathered basic information about a machine, and the output was emailed to the project. Once registered, users received an annual reminder to update information in their entry (despite using Linux since before the 1.0 release, user #46406 didn’t register until 2001).
When it closed (reopened/closed/coming back) it had 120K+ registered users. That’s a lot of information about computers, which unfortunately is not publicly available. I have not had any replies to my emails to those involved, asking for a copy that could be released in anonymized form.
This week I found 15,906 rows of what looks like a subset of the Linux counter data, most entries are post-2005. What did I learn from this data?
An obvious use is the pattern to check is changes over time. While the data does not include any explicit date, it does include the Kernel version, from which the earliest date can be inferred.
An earlier post used SPEC data to estimate the growth in installed memory over time; it has been doubling every 840 days, give or take. That data contains one data point per distinct vendor computer; the Linux counter data contains one entry per computer in use. There is around thirty pairs of entries for updated systems, i.e., a user updated the entry for an existing system.
The plot below shows memory installed in each registered computer, over time, for servers, laptops and workstations, with fitted regression lines. The memory size doubling times are: servers 4,000 days, laptops 2,000 days, and workstations 1,300 days (code+data):
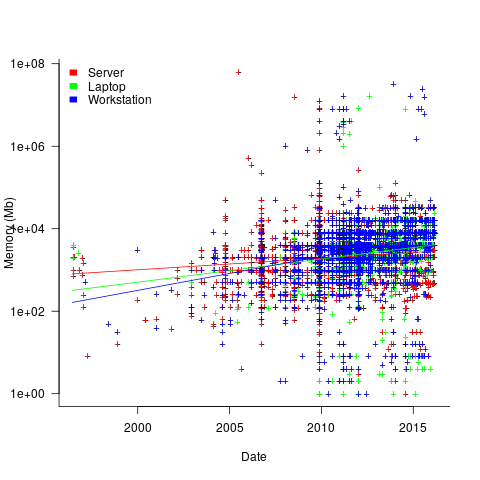
A regression model using dates is a good fit in the statistical sense, but explain very little of the variance in the data. The actual date on which the memory size was selected may have been earlier (because the kernel has been updated to a later release), or later (because memory was added, but the kernel was not updated).
Why is the memory doubling time so long?
Has memory size now reached the big-enough boundary, do Linux counter users keep the same system for many years without upgrading, are Linux counter systems retired Windows boxes that have been repurposed (data on installed memory Windows boxes would answer this point)?
Suggestions welcome.
When memory capacity is limited, it may be useful to swap least recently used memory contents to disc; Linux setup includes the specification of a swap partition. What is the optimal size of the size partition? A common recommendation is: if memory is less than 2G swap size is twice memory; if between 2-8G swap size is the same as memory, and for greater than 8G, half of memory size. The table below shows the percentage of particular system classes having a given swap/memory ratio (rounding the list of ratios to contain one decimal digit produces a list of over 100 ratio values).
swap/memory Server Workstation Laptop
1.0 15.2 19.9 25.9
2.0 10.3 9.6 8.6
0.5 9.5 7.7 8.4
The plot below shows memory against swap partition size, for the system classes laptop, server and workstation, with fitted regression line (code+data):
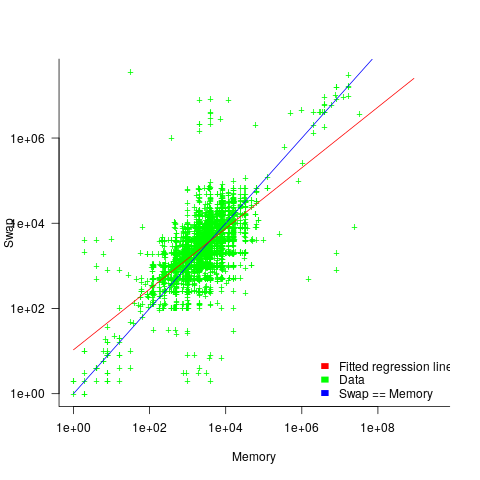
The available disk space also has a (small) impact on swap partition size; the following model explains 46% of the variance in the data:  .
.
I was hoping to confirm the rate of installed memory growth suggested by the SPEC data, with installed systems lagging a few years behind the latest releases. This Linux counter data tells a very different growth story. Perhaps pre-2005 data will tell another story (I just need to find it).
I’m not sure if the swap/memory ratio analysis is of any use to systems people. It was something of a fishing expedition on my part.
Other counting projects have included the Ubuntu counter project, and Hardware for Linux which is still active and goes back to August 2014.
I’m interested in hearing about the availability of any other Linux counter data, or data from other computer counting projects.