Derek Jones from The Shape of Code
Sorting and searching are probably the most widely performed operations in computing; they are extensively covered in volume 3 of The Art of Computer Programming. Algorithm performance is influence by the characteristics of the processor on which it runs, and the size of the processor cache(s) has a significant impact on performance.
A study by Khuong and Morin investigated the performance of various search algorithms on 46 different processors. Khuong kindly sent me a copy of the raw data; the study webpage includes lots of plots.
The performance comparison involved 46 processors (mostly Intel x86 compatible cpus, plus a few ARM cpus) times 3 array datatypes times 81 array sizes times 28 search algorithms. First a 32/64/128-bit array of unsigned integers containing N elements was initialized with known values. The benchmark iterated 2-million times around randomly selecting one of the known values, and then searching for it using the algorithm under test. The time taken to iterate 2-million times was recorded. This was repeated for the 81 values of N, up to 63,095,734, on each of the 46 processors.
The plot below shows the results of running each algorithm benchmarked (colored lines) on an Intel Atom D2700 @ 2.13GHz, for 32-bit array elements; the kink in the lines occur roughly at the point where the size of the array exceeds the cache size (all code+data):
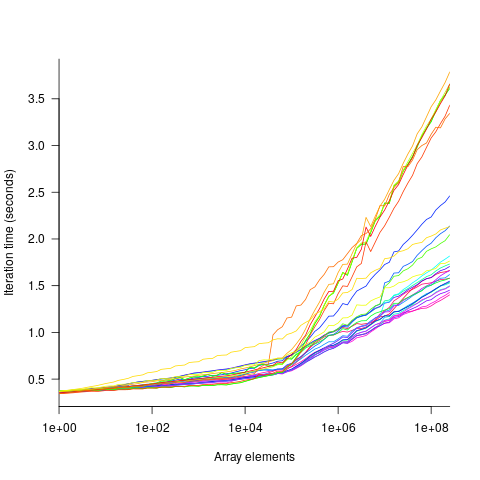
What is the most effective way of analyzing the measurements to produce consistent results?
One approach is to build two regression models, one for the measurements before the cache ‘kink’ and one for the measurements after this kink. By adding in a dummy variable at the kink-point, it is possible to merge these two models into one model. The problem with this approach is that the kink-point has to be chosen in advance. The plot shows that the performance kink occurs before the array size exceeds the cache size; other variables are using up some of the cache storage.
This approach requires fitting 46*3=138 models (I think the algorithm used can be integrated into the model).
If data from lots of processors is to be fitted, or the three datatypes handled, an automatic way of picking where the first regression model should end, and where the second regression model should start is needed.
Regression discontinuity design looks like it might be applicable; treating the point where the array size exceeds the cache size as the discontinuity. Traditionally discontinuity designs assume a sharp discontinuity, which is not the case for these benchmarks (R’s rdd package worked for one algorithm, one datatype running on one processor); the more recent continuity-based approach supports a transition interval before/after the discontinuity. The R package rdrobust supports a continued-based approach, but seems to expect the discontinuity to be a change of intercept, rather than a change of slope (or rather, I could not figure out how to get it to model a just change of slope; suggestions welcome).
Another approach is to use segmented regression, i.e., one of more distinct lines. The package segmented supports fitting this kind of model, and does estimate what they call the breakpoint (the user has to provide a first estimate).
I managed to fit a segmented model that included all the algorithms for 32-bit data, running on one processor (code+data). Looking at the fitted model I am not hopeful that adding data from more than one processor would produce something that contained useful information. I suspect that there are enough irregular behaviors in the benchmark runs to throw off fitting quality.
I’m always asking for more data, and now I have more data than I know how to analyze in a way that does not require me to build 100+ models 
Suggestions welcome.
 , or
, or 
 (values taken from the first column of numbers above).
(values taken from the first column of numbers above). , while for
, while for  . So
. So }") , i.e., between 2.2 and 4.9 (the multiplication by 1.96 is used to give a 95% confidence interval); the
, i.e., between 2.2 and 4.9 (the multiplication by 1.96 is used to give a 95% confidence interval); the }") , between 0.3 and 0.6.
, between 0.3 and 0.6.