Derek Jones from The Shape of Code
If a mistake is spotted in the source code of a shipping software system, is it more cost-effective to fix the mistake, or to wait for a customer to report a fault whose root cause turns out to be that particular coding mistake?
The naive answer is don’t wait for a customer fault report, based on the following simplistic argument:  .
.
where:  is the cost of fixing the mistake in the code (including testing etc), and
is the cost of fixing the mistake in the code (including testing etc), and  is the cost of finding the mistake in the code based on a customer fault report (i.e., the sum on the right is the total cost of fixing a fault reported by a customer).
is the cost of finding the mistake in the code based on a customer fault report (i.e., the sum on the right is the total cost of fixing a fault reported by a customer).
If the mistake is spotted in the code for ‘free’, then  , e.g., a developer reading the code for another reason, or flagged by a static analysis tool.
, e.g., a developer reading the code for another reason, or flagged by a static analysis tool.
This answer is naive because it fails to take into account the possibility that the code containing the mistake is deleted/modified before any customers experience a fault caused by the mistake; let  be the likelihood that the coding mistake ceases to exist in the next unit of time.
be the likelihood that the coding mistake ceases to exist in the next unit of time.
The more often the software is used, the more likely a fault experience based on the coding mistake occurs; let  be the likelihood that a fault is reported in the next time unit.
be the likelihood that a fault is reported in the next time unit.
A more realistic analysis takes into account both the likelihood of the coding mistake disappearing and a corresponding fault being reported, modifying the relationship to: *{F_{experience}/M_{gone}}")
Software systems are eventually retired from service; the likelihood that the software is maintained during the next unit of time,  , is slightly less than one.
, is slightly less than one.
Giving the relationship: *{F_{experience}/M_{gone}}*S_{maintained}")
which simplifies to: *{F_{experience}/M_{gone}}*S_{maintained}")
What is the likely range of values for the ratio:  ?
?
I have no find/fix cost data, although detailed total time is available, i.e., find+fix time (with time probably being a good proxy for cost). My personal experience of find often taking a lot longer than fix probably suffers from survival of memorable cases; I can think of cases where the opposite was true.
The two values in the ratio  are likely to change as a system evolves, e.g., high code turnover during early releases that slows as the system matures. The value of should decrease over time, but increase with a large influx of new users.
are likely to change as a system evolves, e.g., high code turnover during early releases that slows as the system matures. The value of should decrease over time, but increase with a large influx of new users.
A study by Penta, Cerulo and Aversano investigated the lifetime of coding mistakes (detected by several tools), tracking them over three years from creation to possible removal (either fixed because of a fault report, or simply a change to the code).
Of the 2,388 coding mistakes detected in code developed over 3-years, 41 were removed as reported faults and 416 disappeared through changes to the code: 
The plot below shows the survival curve for memory related coding mistakes detected in Samba, based on reported faults (red) and all other changes to the code (blue/green, code+data):
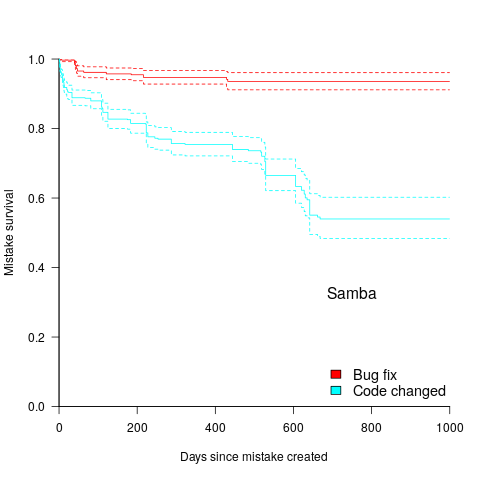
Coding mistakes are obviously being removed much more rapidly due to changes to the source, compared to customer fault reports.
For it to be cost-effective to fix coding mistakes in Samba, flagged by the tools used in this study ( is essentially one), requires:  .
.
Meeting this requirement does not look that implausible to me, but obviously data is needed.