Derek Jones from The Shape of Code
One of the methods I used to try to work out what statistical techniques were likely to be useful to software developers, was to try to apply techniques that were useful in other areas. Of course, applying techniques requires the appropriate data to apply them to.
Extreme value statistics are used to spot patterns in rare events, e.g., frequency of rivers over spilling their banks and causing extensive flooding. I have tried and failed to find any data where Extreme value theory might be applicable. There probably is some such data, somewhere.
The fact that I have spent a lot of time looking for data and failed to find particular kinds of data, suggests that occurrences are rare. If data needing a particular kind of analysis technique is rare, there is no point including a discussion of the technique in a book aimed at providing general coverage of material.
I have spent some time looking for data drawn from a zero-inflated Poisson distribution. Readers are unlikely to have ever heard of this and might well ask why I would be interested in such an obscure distribution. Well, zero-truncated Poisson distributions crop up regularly (the Poisson distribution applies to count data that starts at zero, when count data starts at one the zeroes are said to be truncated and the Poisson distribution has to be offset to adjust for this). There is a certain symmetry to zero-truncated/inflated (although the mathematics involved is completely different), plus there is probably a sunk cost effect (i.e., I have spent time learning about them, I am going to find the data).
I spotted a plot in a paper investigating record data structure usage in Racket, that looked like it might be well fitted by a zero-inflated Poisson distribution. Tobias Pape kindly sent me the data (number of record data structures having a given size), which I then failed miserably to fit to any kind of Poisson related distribution; see plot below; data points along red line through the plus symbols (code+data):
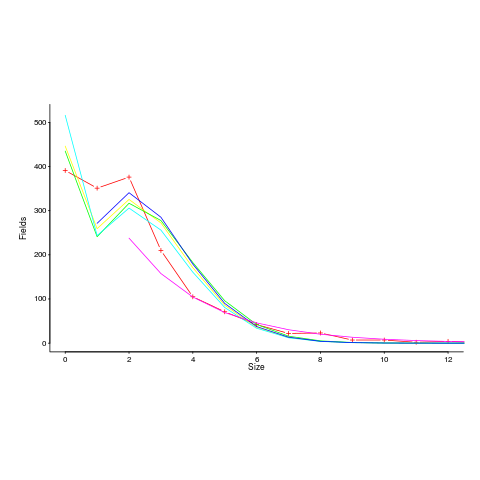
I can only imagine what the authors thought of my reason for wanting the data (I made data requests to a few other researchers for similar reasons; and again I failed to fit the desired distribution).
I had expected to make more use of time series analysis; but, it has just not been that applicable.
Machine learning is useful for publishing papers, but understanding what is going on is the subject of my book, not building black boxes to make predictions.
It is possible that researchers are not publishing work relating to data that requires statistical techniques I have not used, because they don’t know how to analyze the data or the data is too hard to collect. Inability to use the correct techniques to analyze data is rarely a reason for not publishing a paper. Data being too hard to collect is very believable, as-is the data rarely occurring in software engineering related work.
There are statistical tests I have intentionally ignored, the Mann–Whitney U test (aka, the Wilcoxon rank-sum test) and the t-test probably being the most well-known. These tests became obsolete once computers became generally available. If you are ever stuck on a desert island without a computer, these are the statistical tests you will have to use.