Derek Jones from The Shape of Code
How performance varies with group size is an interesting question that is still an unresearched area of software engineering. The impact of learning is also an interesting question and there has been some software engineering research in this area.
I recently read a very interesting study involving both group size and learning, and Jaakko Peltokorpi kindly sent me a copy of the data.
That is the good news; the not so good news is that the experiment was not about software engineering, but the manual assembly of a contraption of the experimenters devising. Still, this experiment is an example of the impact of group size and learning (through repeating the task).
Subjects worked in groups of one to four people and repeated the task four times. Time taken to assemble a bespoke, floor standing rack with some odd-looking connections between components (the image in the paper shows an image of something that might function as a floor standing book-case, if shelves were added, apart from some component connections getting in the way) was measured.
The following equation is a very good fit to the data (code+data). There is theory explaining why ") applies, but the division by group-size was found by suck-it-and-see (in another post I found that time spent planning increased with teams size).
applies, but the division by group-size was found by suck-it-and-see (in another post I found that time spent planning increased with teams size).
There is a strong repetition/group-size interaction. As the group size increases, repetition has less of an impact on improving performance.
![time = 0.16+ 0.53/{group size} - log(repetitions)*[0.1 + {0.22}/{group size}]](http://shape-of-code.coding-guidelines.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_980.5_b0d171bba046801a68ce5dc8ae1d6115.png "time = 0.16+ 0.53/{group size} - log(repetitions)*[0.1 + {0.22}/{group size}]")
The following plot shows one way of looking at the data (larger groups take less time, but the difference declines with practice):
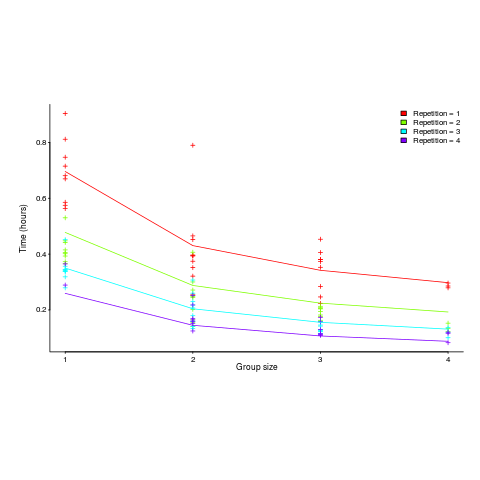
and here is another (a group of two is not twice as fast as a group of one; with practice smaller groups are converging on the performance of larger groups):
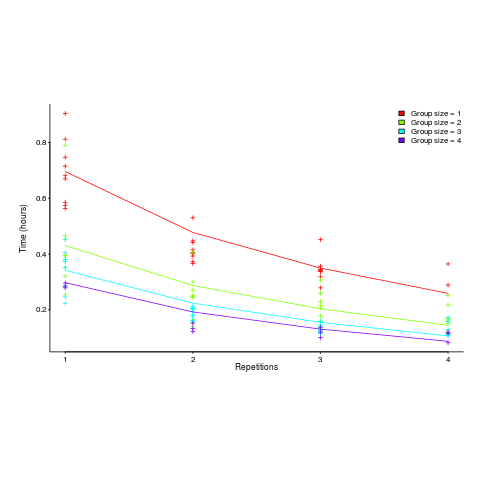
Would the same kind of equation fit the results from solving a software engineering task? Hopefully somebody will run an experiment to find out 
