Derek Jones from The Shape of Code
During software development, when a mistake has been made it may be corrected soon after it is made, much later during development, by the customer in a shipped product, or never corrected.
If a mistake is corrected, the cost of correction increases as the ‘distance’ between its creation and detection increases. In a phased development model, the distance might be the number of phases between creation and detection; in a throw it at the wall and see if it sticks development model, the distance might be the number of dependencies on the ‘mistake’ code.
There are people who claim that detecting mistakes earlier will save money. This claim overlooks the cost of detecting mistakes, and in some cases earlier detection is likely to be more expensive (or the distribution of people across phases may rate limit what can be done in any phase). For instance, people might not be willing to read requirements documents, but be willing to try running software; some coding mistakes are only going to be encountered later during integration test, etc.
Folklore claims of orders of magnitude increases in fixing cost, as ‘distance’ increases, have been shown to be hand waving.
I know of two datasets on ‘distance’ between mistake creation and detection. A tiny dataset in Implementation of Fault Slip Through in Design Phase of the Project (containing only counts information; also see figure 6.41), and the CESAW dataset.
The plot below shows the time taken to fix 7,000 reported defects by distance between phases, for CESAW project 615 (code+data). The red lines are fitted regression models of the form  , for minimum fix times of 1, 5 and 10 minutes:
, for minimum fix times of 1, 5 and 10 minutes:
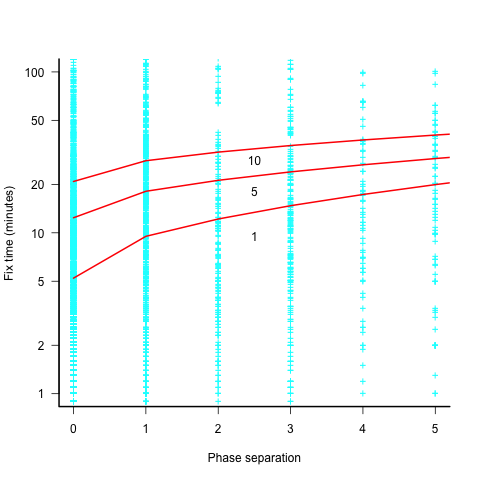
The above plot makes various simplifying assumptions, including: ‘sub-phases’ being associated with a ‘parent’ phase selected by your author, and the distance between all pairs of adjacent phase is the same (in terms of their impact on fix time).
A more sophisticated data model might change the functional form of the fitted regression model, but is unlikely to remove the general upward trend.
There are lots of fix times taking less than five minutes. Project 615 developed safety critical software, and so every detected mistake was recorded; on other projects, small mistakes would probably been fixed without an associated formal record.
I think that, if it were not for the, now discredited, folklore claiming outsized relative costs for fixing reported defects at greater ‘distances’ from the introduction of a mistake, this issue would be a niche topic.

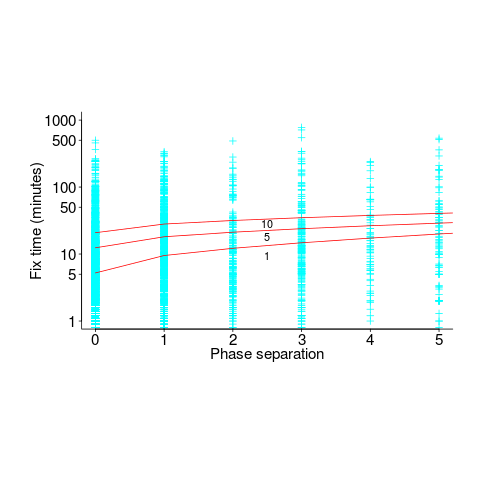
 ) explains just 6% of the variance in the data, i.e., there is a small increase with phase separation, but it is almost down in the noise.
) explains just 6% of the variance in the data, i.e., there is a small increase with phase separation, but it is almost down in the noise. , and improves the model by less than 1-percent.
, and improves the model by less than 1-percent. , improves the variance explained to 14% (better than a poke in the eye, just). The fitted value of
, improves the variance explained to 14% (better than a poke in the eye, just). The fitted value of  varies between 0.66 and 1.4 (factor of two, human variation).
varies between 0.66 and 1.4 (factor of two, human variation).