Derek Jones from The Shape of Code
I was at the Zero-Knowledge proofs workshop run by BinaryDistict on Monday and Tuesday. The workshop runs all week, but is mostly hacking for the remaining days (hacking would be interesting if I had a problem to code, more about this at the end).
Zero-knowledge proofs allow person A to convince person B, that A knows the value of x, without revealing the value of x. There are two kinds of zero-knowledge proofs: an interacting proof system involves a sequence of messages being exchanged between the two parties, and in non-interactive systems (the primary focus of the workshop), there is no interaction.
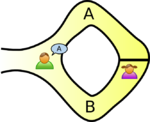
The example usually given, of a zero-knowledge proof, involves Peggy and Victor. Peggy wants to convince Victor that she knows how to unlock the door dividing a looping path through a tunnel in a cave.
The ‘proof’ involves Peggy walking, unseen by Victor, down path A or B (see diagram below; image from Wikipedia). Once Peggy is out of view, Victor randomly shouts out A or B; Peggy then has to walk out of the tunnel using the path Victor shouted; there is a 50% chance that Peggy happened to choose the path selected by Victor. The proof is iterative; at the end of each iteration, Victor’s uncertainty of Peggy’s claim of being able to open the door is reduced by 50%. Victor has to iterate until he is sufficiently satisfied that Peggy knows how to open the door.
As the name suggests, non-interactive proofs do not involve any message passing; in the common reference string model, a string of symbols, generated by person making the claim of knowledge, is encoded in such a way that it can be used by third-parties to verify the claim of knowledge. At the workshop we got an overview of zk-SNARKs (zero-knowledge succinct non-interactive argument of knowledge).
The ‘succinct’ component of zk-SNARK is what has made this approach practical. When non-interactive proofs were first proposed, the arguments of knowledge contained around one-terabyte of data; these days common reference strings are around a kilobyte.
The fact that zero-knowledge ‘proof’s are possible is very interesting, but do they have practical uses?
The hackathon aspect of the workshop was designed to address the practical use issue. The existing zero-knowledge proofs tend to involve the use of prime numbers, or the factors of very large numbers (as might be expected of a proof system that was heavily based on cryptography). Making use of zero-knowledge proofs requires mapping the problem to a form that has a known solution; this is very hard. Existing applications involve cryptography and block-chains (Zcash is a cryptocurrency that has an option that provides privacy via zero-knowledge proofs), both heavy users of number theory.
The workshop introduced us to two languages, which could be used for writing zero-knowledge applications; ZoKrates and snarky. The weekend before the workshop, I tried to install both languages: ZoKrates installed quickly and painlessly, while I could not get snarky installed (I was old that the first two hours of the snarky workshop were spent getting installs to work); I also noticed that ZoKrates had greater presence than snarky on the web, in the form of pages discussing the language. It seemed to me that ZoKrates was the market leader. The workshop presenters included people involved with both languages; Jacob Eberhardt (one of the people behind ZoKrates) gave a great presentation, and had good slides. Team ZoKrates is clearly the one to watch.
As an experienced hack attendee, I was ready with an interesting problem to solve. After I explained the problem to those opting to use ZoKrates, somebody suggested that oblivious transfer could be used to solve my problem (and indeed, 1-out-of-n oblivious transfer does offer the required functionality).
My problem was: Let’s say I have three software products, the customer has a copy of all three products, and is willing to pay the license fee to use one of these products. However, the customer does not want me to know which of the three products they are using. How can I send them a product specific license key, without knowing which product they are going to use? Oblivious transfer involves a sequence of message exchanges (each exchange involves three messages, one for each product) with the final exchange requiring that I send three messages, each containing a separate product key (one for each product); the customer can only successfully decode the product-specific message they had selected earlier in the process (decoding the other two messages produces random characters, i.e., no product key).
Like most hackathons, problem ideas were somewhat contrived (a few people wanted to delve further into the technical details). I could not find an interesting team to join, and left them to it for the rest of the week.
There were 50-60 people on the first day, and 30-40 on the second. Many of the people I spoke to were recent graduates, and half of the speakers were doing or had just completed PhDs; the field is completely new. If zero-knowledge proofs take off, decisions made over the next year or two by the people at this workshop will impact the path the field follows. Otherwise, nothing happens, and a bunch of people will have interesting memories about stuff they dabbled in, when young.