Derek Jones from The Shape of Code
When asked for an estimate of the time needed to complete a task, should developers be free to choose any numeric value, or should they be restricted to selecting from a predefined set of values (e.g, the Fibonacci numbers, or T-shirt sizes)?
Allowing any value to be chosen would appear to provide the greatest flexibility to make an accurate estimate. However, estimating is an intrinsically uncertain process (i.e., the future is unknown), and it is done by people with varying degrees of experience (which might be used to help guide their prediction about the future).
Restricting the selection process to one of the values in a granular sequence of numbers has several benefits, including:
- being able to adjust the gaps between permitted values to match the likely level of uncertainty in the task effort, or the best accuracy resolution believed possible,
- reducing the psychological stress of making an estimate, by explicitly giving permission to ignore the smaller issues (because they are believed to require a total effort that is less than the sequence granularity),
- helping to maintain developer self-esteem, by providing a justification when an estimate turning out to be inaccurate, e.g., the granularity prevented a more accurate estimate being made.
Is there an optimal sequence of granular values to use when making task estimates for a project?
The answer to this question depends on what is attempting to be optimized.
Given how hard it is to get people to produce estimates, the first criterion for an optimal sequence has to be that people are willing to use it.
I have always been struck by the ritualistic way in which the Fibonacci sequence is described by those who use it to make estimates. Rituals are an effective technique used by groups to help maintain members’ adherence to group norms (one of which might be producing estimates).
A possible reason for the tendency to use round numbers might estimate-values is that this usage is common in other social interactions involving numeric values, e.g., when replying to a request for the time of day.
The use of round numbers, when developers have the option of selecting from a continuous range of values, is a developer imposed granular sequence. What form do these round number sequences take?
The plot below shows the values of each of the six most common round number estimates present in the BrightSquid, SiP, and CESAW (project 615) effort estimation data sets, plus the first six Fibonacci numbers (code+data):
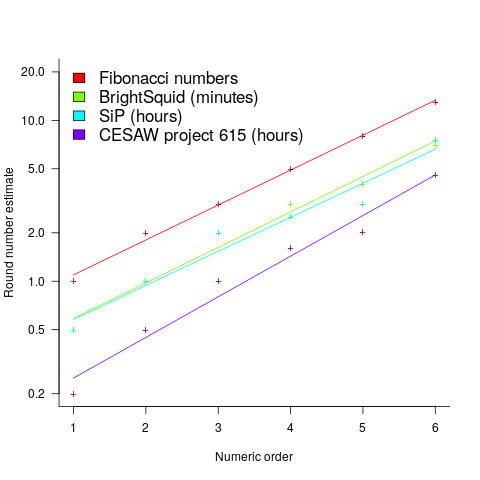
The lines are fitted regression models having the form:  (there is a small variation in the value of the constant; the smallest value for project 615 was probably calculated rather than being human selected).
(there is a small variation in the value of the constant; the smallest value for project 615 was probably calculated rather than being human selected).
This plot shows a consistent pattern of use across multiple projects (I know of several projects that use Fibonacci numbers, but don’t have any publicly available data). Nothing is said about this pattern being (near) optimal in any sense.
The time unit of estimation for this data was minutes or hours. Would the equation have the same form if the time unit was days, would the constant still be around  . I await the data needed to answer this question.
. I await the data needed to answer this question.
This brief analysis looked at granular sequences from the perspective of the distribution of estimates made. Perhaps it makes more sense to base a granular estimation sequence on the distribution of actual task effort. A topic for another post.
 (there is a small variation in the value of the constant; the smallest value for project 615 was probably calculated rather than being human selected).
(there is a small variation in the value of the constant; the smallest value for project 615 was probably calculated rather than being human selected). . I await the data needed to answer this question.
. I await the data needed to answer this question.