Derek Jones from The Shape of Code
AI (a.k.a. machine learning) is a compute intensive activity, with the performance of trained models being dependent on the quantity of compute used to train the model.
Given the ongoing history of continually increasing compute power, what is the maximum compute power that might be available to train ML models in the coming years?
How might the compute resources used to train an ML model be measured?
One obvious answer is to specify the computers used and the numbers of days used they were occupied training the model. The problem with this approach is that the differences between the computers used can be substantial. How is compute power measured in other domains?
Supercomputers are ranked using FLOPS (floating-point operations per second), or GigFLOPS or PetaFLOPS ( ). The Top500 list gives values for
). The Top500 list gives values for  (based on benchmark performance, i.e., LINNPACK) and
(based on benchmark performance, i.e., LINNPACK) and  (what the hardware is theoretically capable of, which is sometimes more than twice ).
(what the hardware is theoretically capable of, which is sometimes more than twice ).
A ballpark approach to measuring the FLOPS consumed by an application is to estimate the FLOPS consumed by the computers involved and multiply by the number of seconds each computer was involved in training. The huge assumption made with this calculation is that the application actually consumes all the FLOPS that the hardware is capable of supplying. In some cases this appears to be the metric used to estimate the compute resources used to train an ML model. Some published papers just list a FLOPS value, while others list the number of GPUs used (e.g., 2,128).
A few papers attempt a more refined approach. For instance, the paper describing the GPT-3 models derives its FLOPS values from quantities such as the number of parameters in each model and number of training tokens used. Presumably, the research group built a calibration model that provided the information needed to estimate FLOPS in this way.
How does one get to be able to use PetaFLOPS of compute to train a model (training the GPT-3 175B model consumed 3,640 PetaFLOP days, or around a few days on a top 8 supercomputer)?
Pay what it costs. Money buys cloud compute or bespoke supercomputers (which are more cost-effective for large scale tasks, if you have around £100million to spend plus £10million or so for the annual electricity bill). While the amount paid to train a model might have lots of practical value (e.g., can I afford to train such a model), researchers might not be keen to let everybody know how much they spent. For instance, if a research team have a deal with a major cloud provider to soak up any unused capacity, those involved probably have no interest in calculating compute cost.
How has the compute power used to train ML models increased over time? A recent paper includes data on the training of 493 models, of which 129 include estimated FLOPS, and 106 contain date and model parameter data. The data comes from published papers, and there are many thousands of papers that train ML models. The authors used various notability criteria to select papers, and my take on the selection is that it represents the high-end of compute resources used over time (which is what I’m interested in). While they did a great job of extracting data, there is no real analysis (apart from fitting equations).
The plot below shows the FLOPS training budget used/claimed/estimated for ML models described in papers published on given dates; lines are fitted regression models, and the colors are explained below (code+data):
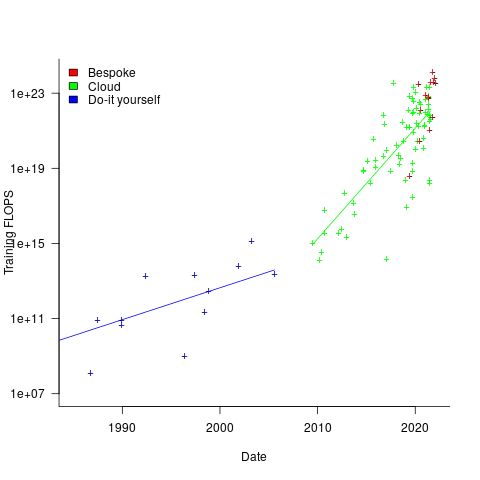
My interpretation of the data is based on the economics of accessing compute resources. I see three periods of development:
- do-it yourself (18 data points): During this period most model builders only had access to a university computer, desktop machines, or a compute cluster they had self-built,
- cloud (74 data points): Huge on demand compute resources are now just a credit card away. Researchers no longer have to wait for congested university computers to become available, or build their own systems.
AWS launched in 2006, and the above plot shows a distinct increase in compute resources around 2008.
- bespoke (14 data points): if the ML training budget is large enough, it becomes cost-effective to build a bespoke system, e.g., a supercomputer. As well as being more cost-effective, a bespoke system can also be specifically designed to handle the characteristics of the kinds of applications run.
How might models trained using a bespoke system be distinguished from those trained using cloud compute? The plot below shows the number of parameters in each trained model, over time, and there is a distinct gap between
 and
and  parameters, which I assume is the result of bespoke systems having the memory capacity to handle more parameters (code+data):
parameters, which I assume is the result of bespoke systems having the memory capacity to handle more parameters (code+data):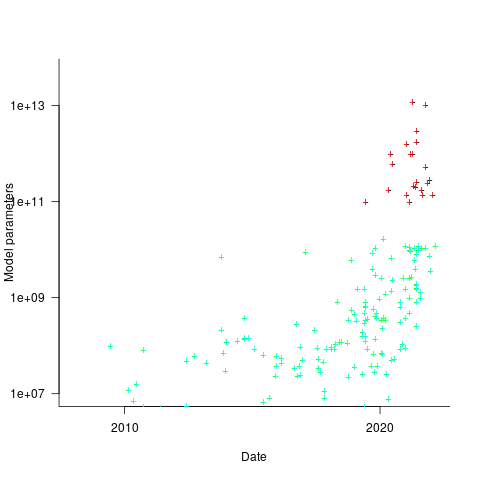
The rise in FLOPS growth rate during the Cloud period comes from several sources: 1) the exponential decline in the prices charged by providers delivers researchers an exponentially increasing compute for the same price, 2) researchers obtaining larger grants to work on what is considered to be an important topic, 3) researchers doing deals with providers to make use of excess capacity.
The rate of growth of Cloud usage is capped by the cost of building a bespoke system. The future growth of Cloud training FLOPS will be constrained by the rate at which the prices charged for a FLOP decreases (grants are unlikely to continually increase substantially).
The rate of growth of the Top500 list is probably a good indicator of the rate of growth of bespoke system performance (and this does appear to be slowing down). Perhaps specialist ML training chips will provide performance that exceeds that of the GPU chips currently being used.
The maximum compute that can be used by an application is set by the reliability of the hardware and the percentage of resources used to recover from hard errors that occur during a calculation. Supercomputer users have been facing the possibility of hitting the wall of maximum compute for over a decade. ML training is still a minnow in the supercomputer world, where calculations run for months, rather than a few days.