Derek Jones from The Shape of Code
Earlier this week I was reading a paper discussing one aspect of the legal fallout around the UK Post-Office’s Horizon IT system, and was surprised to read the view that the Law Commission’s Evidence in Criminal Proceedings Hearsay and Related Topics were citing on the subject of computer evidence (page 204): “most computer error is either immediately detectable or results from error in the data entered into the machine”.
What? Do I need to waste any time explaining why this is nonsense? It’s obvious nonsense to anybody working in software development, but this view is being expressed in law related documents; what do lawyers know about software development.
Sometimes fallacies become accepted as fact, and a lot of effort is required to expunge them from cultural folklore. Regular readers of this blog will have seen some of my posts on long-standing fallacies in software engineering. It’s worth collecting together some primary evidence that most software mistakes are not immediately detectable.
A paper by Professor Tapper of Oxford University is cited as the source (yes, Oxford, home of mathematical orgasms in software engineering). Tapper’s job title is Reader in Law, and on page 248 he does say: “This seems quite extraordinarily lax, given that most computer error is either immediately detectable or results from error in the data entered into the machine.” So this is not a case of his words being misinterpreted or taken out of context.
Detecting many computer errors is resource intensive, both in elapsed time, manpower and compute time. The following general summary provides some of the evidence for this assertion.
Two events need to occur for a fault experience to occur when running software:
- a mistake has been made when writing the source code. Mistakes include: a misunderstanding of what the behavior should be, using an algorithm that does not have the desired behavior, or a typo,
- the program processes input values that interact with a coding mistake in a way that produces a fault experience.
That people can make different mistakes is general knowledge. It is my experience that people underestimate the variability of the range of values that are presented as inputs to a program.
A study by Nagel and Skrivan shows how variability of input values results in fault being experienced at different time, and that different people make different coding mistakes. The study had three experienced developers independently implement the same specification. Each of these three implementations was then tested, multiple times. The iteration sequence was: 1) run program until fault experienced, 2) fix fault, 3) if less than five faults experienced, goto step (1). This process was repeated 50 times, always starting with the original (uncorrected) implementation; the replications varied this, along with the number of inputs used.
How many input values needed to be processed, on average, before a particular fault is experienced? The plot below (code+data) shows the numbers of inputs processed, by one of the implementations, before individual faults were experienced, over 50 runs (sorted by number of inputs needed before the fault was experienced):
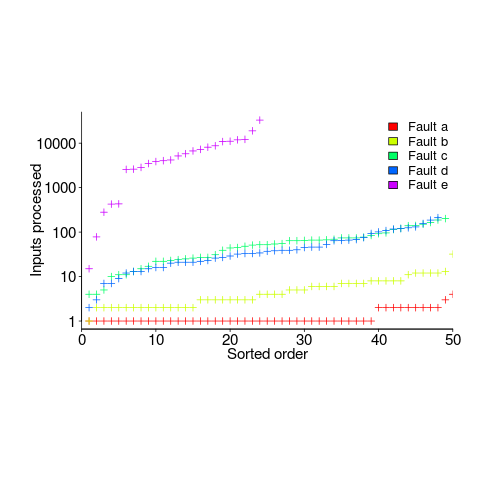
The plot illustrates that some coding mistakes are more likely to produce a fault experience than others (because they are more likely to interact with input values in a way that generates a fault experience), and it also shows how the number of inputs values processed before a particular fault is experienced varies between coding mistakes.
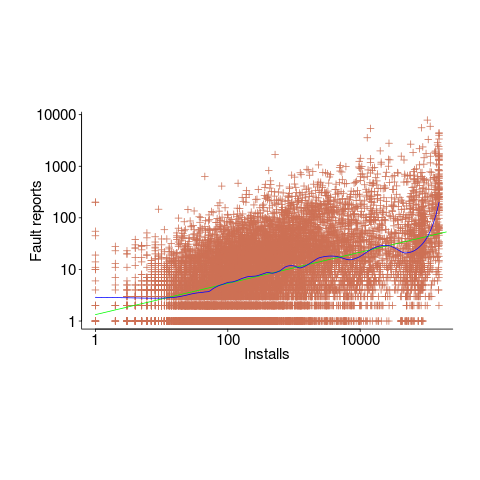
Real-world evidence of the impact of user input on reported faults is provided by the Ultimate Debian Database, which provides information on the number of reported faults and the number of installs for 14,565 packages. The plot below shows how the number of reported faults increases with the number of times a package has been installed; one interpretation is that with more installs there is a wider variety of input values (increasing the likelihood of a fault experience), another is that with more installs there is a larger pool of people available to report a fault experience. Green line is a fitted power law,  , blue line is a fitted loess model.
, blue line is a fitted loess model.
The source containing a mistake may be executed without a fault being experienced; reasons for this include:
- the input values don’t result in the incorrect code behaving differently from the correct code. For instance, given the made-up incorrect code
if (x < 8)(i.e.,8was typed rather than7), the comparison only produces behavior that differs from the correct code whenxhas the value7, - the input values result in the incorrect code behaving differently than the correct code, but the subsequent path through the code produces the intended external behavior.
Some of the studies that have investigated the program behavior after a mistake has deliberately been introduced include:
- checking the later behavior of a program after modifying the value of a variable in various parts of the source; the results found that some parts of a program were more susceptible to behavioral modification (i.e., runtime behavior changed) than others (i.e., runtime behavior not change),
- checking whether a program compiles and if its runtime behavior is unchanged after random changes to its source code (in this study, short programs written in 10 different languages were used),
- 80% of radiation induced bit-flips have been found to have no externally detectable effect on program behavior.
What are the economic costs and benefits of finding and fixing coding mistakes before shipping vs. waiting to fix just those faults reported by customers?
Checking that a software system exhibits the intended behavior takes time and money, and the organization involved may not be receiving any benefit from its investment until the system starts being used.
In some applications the cost of a fault experience is very high (e.g., lowering the landing gear on a commercial aircraft), and it is cost-effective to make a large investment in gaining a high degree of confidence that the software behaves as expected.
In a changing commercial world software systems can become out of date, or superseded by new products. Given the lifetime of a typical system, it is often cost-effective to ship a system expected to contain many coding mistakes, provided the mistakes are unlikely to be executed by typical customer input in a way that produces a fault experience.
Beta testing provides selected customers with an early version of a new release. The benefit to the software vendor is targeted information about remaining coding mistakes that need to be fixed to reduce customer fault experiences, and the benefit to the customer is checking compatibility of their existing work practices with the new release (also, some people enjoy being able to brag about being a beta tester).
- One study found that source containing a coding mistake was less likely to be changed due to fixing the mistake than changed for other reasons (that had the effect of causing the mistake to disappear),
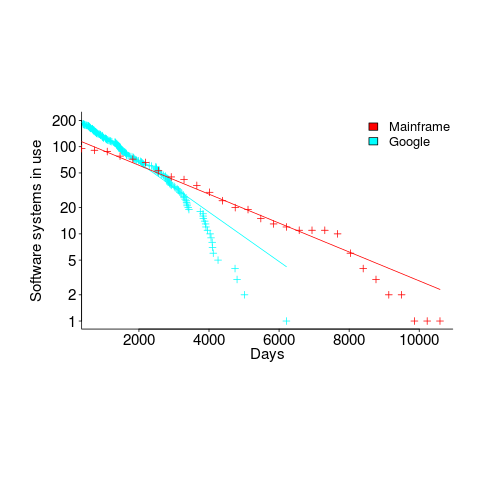
- Software systems don't live forever; systems are replaced or cease being used. The plot below shows the lifetime of 202 Google applications (half-life 2.9 years) and 95 Japanese mainframe applications from the 1990s (half-life 5 years; code+data).
Not only are most coding mistakes not immediately detectable, there may be sound economic reasons for not investing in detecting many of them.