Derek Jones from The Shape of Code
A software estimate is a prediction about the future. Software developers were not the first people to formalize processes for making predictions about the future. Starting in the last 1940s, the RAND Corporation’s Delphi project created what became known as the Delphi method, e.g., An Experiment in Estimation, and Construction of Group Preference Relations by Iteration.
In its original form experts were anonymous; there was a “… deliberate attempt to avoid the disadvantages associated with more conventional uses of experts, such as round-table discussions or other milder forms of confrontation with opposing views.”, and no rules were given for the number of iterations. The questions involved issues whose answers involved long term planning, e.g., how many nuclear weapons did the Soviet Union possess (this study asked five questions, which required five estimates). Experts could provide multiple answers, and had to give a probability for each being true.
One of those involved in the Delphi project (Helmer-Hirschberg) co-founded the Institute for the Future, which published reports about the future based on answers obtained using the Delphi method, e.g., a 1970 prediction of the state-of-the-art of computer development by the year 2000 (Dalkey, a productive member of the project, stayed at RAND).
The first application of Delphi to software estimation was by Farquhar in 1970 (no pdf available), and Boehm is said to have modified the Delphi process to have the ‘experts’ meet together, rather than be anonymous, (I don’t have a copy of Farquhar, and my copy of Boehm’s book is in a box I cannot easily get to); this meeting together form of Delphi is known as Wideband Delphi.
Planning poker is a variant of Wideband Delphi.
An assessment of Delphi by Sackman (of Grant-Sackman fame) found that: “Much of the popularity and acceptance of Delphi rests on the claim of the superiority of group over individual opinions, and the preferability of private opinion over face-to-face confrontation.” The Oracle at Delphi was one person, have we learned something new since that time?
Group dynamics is covered in section 3.4 of my Evidence-based software engineering book; resource estimation is covered in section 5.3.
The likelihood that a group will outperform an individual has been found to depend on the kind of problem. Is software estimation the kind of problem where a group is likely to outperform an individual? Obviously it will depend on the expertise of those in the group, relative to what is being estimated.
What does the evidence have to say about the accuracy of the Delphi method and its spinoffs?
When asked to come up with a list of issues associated with solving a problem, groups generate longer lists of issues than individuals. The average number of issues per person is smaller, but efficient use of people is not the topic here. Having a more complete list of issues ought to be good for accurate estimating (the validity of the issues is dependent on the expertise of those involved).
There are patterns of consistent variability in the estimates made by individuals; some people tend to consistently over-estimate, while others consistently under-estimate. A group will probably contain a mixture of people who tend to over/under estimate, and an iterative estimation process that leads to convergence is likely to produce a middling result.
By how much do some people under/over estimate?
The multiplicative factor values (y-axis) appearing in the plot below are from a regression model fitted to estimate/actual implementation time for a project involving 13,669 tasks and 47 developers (data from a study Nichols, McHale, Sweeney, Snavely and Volkmann). Each vertical line, or single red plus, is one person (at least four estimates needed to be made for a red plus to occur); the red pluses are the regression model’s multiplicative factor for that person’s estimates of a particular kind of creation task, e.g., design, coding, or testing. Points below the grey line are overestimation, and above the grey line the underestimation (code+data):
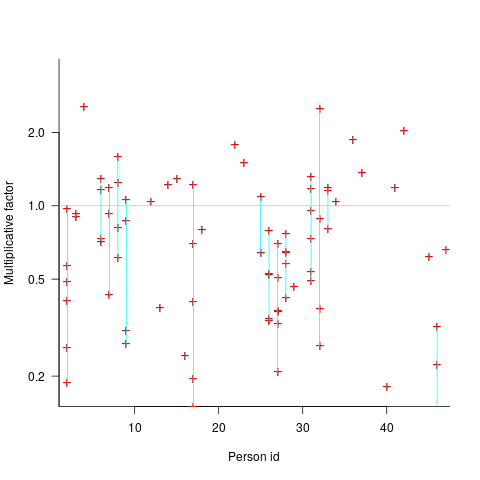
What is the probability of a Delphi estimate being more accurate than an individual’s estimate?
If we assume that a middling answer is more likely to be correct, then we need to calculate the probability that the mix of people in a Delphi group produces a middling estimate while the individual produces a more extreme estimate.
I don’t have any Wideband Delphi estimation data (or rather, I only have tiny amounts); pointers to such data are most welcome.