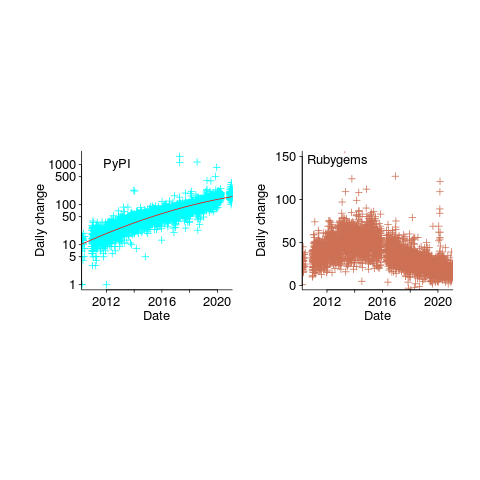Derek Jones from The Shape of Code
A software system can be said to be dead when the information needed to run it ceases to be available.
Provided the necessary information is available, plus time/money, no software ever has to remain dead, hardware emulators can be created, support libraries can be created, and other necessary files cobbled together.
In the case of software as a service, the vendor may simply stop supplying the service; after which, in my experience, critical components of the internal service ecosystem soon disperse and are forgotten about.
Users like the software they use to be actively maintained (i.e., there are one or more developers currently working on the code). This preference is culturally driven, in that we are living through a period in which most in-use software systems are actively maintained.
Active maintenance is perceived as a signal that the software has some amount of popularity (i.e., used by other people), and is up-to-date (whatever that means, but might include supporting the latest features, or problem reports are being processed; neither of which need be true). Commercial users like actively maintained software because it enables the option of paying for any modifications they need to be made.
Software can be a zombie, i.e., neither dead or alive. Zombie software will continue to work for as long as the behavior of its external dependencies (e.g., libraries) remains sufficiently the same.
Active maintenance requires time/money. If active maintenance is required, then invest the time/money.
Open source software has become widely used. Is Open source software frequently maintained, or do projects inhabit some form of zombie state?
Researchers have investigated various aspects of the life cycle of open source projects, including: maintenance activity, pull acceptance/merging or abandoned, and turnover of core developers; also, projects in niche ecosystems have been investigated.
The commits/pull requests/issues, of circa 1K project repos with lots of stars, is data that can be automatically extracted and analysed in bulk. What is missing from the analysis is the context around the creation, development and apparent abandonment of these projects.
Application areas and development tools (e.g., editor, database, gui framework, communications, scientific, engineering) tend to have a few widely used programs, which continue to be actively worked on. Some people enjoy creating programs/apps, and will start development in an area where there are existing widely used programs, purely for the enjoyment or to scratch an itch; rarely with the intent of long term maintenance, even when their project attracts many other developers.
I suspect that much of the existing research is simply measuring the background fizz of look-alike programs coming and going.
A more realistic model of the lifecycle of Open source projects requires human information; the intent of the core developers, e.g., whether the project is intended to be long-term, primarily supported by commercial interests, abandoned for a successor project, or whether events got in the way of the great things planned.
 The following are the most interesting items I discovered during a fishing expedition.
The following are the most interesting items I discovered during a fishing expedition. , where
, where  is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all
is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all