Derek Jones from The Shape of Code
How many minutes past the hour was it, when you stopped working on some software related task?
There are sixty minutes in an hour, so if stop times are random, the probability of finishing at any given minute is 1-in-60. If practice (based on the 200k+ time records in the CESAW dataset) the probability of stopping on the hour is 1-in-40, and for stopping on the half-hour is 1-in-48.
Why are developers more likely to stop working on a task, on the hour or half-hour?
Is this a case of Parkinson’s law, or are developers striving to complete a task within a specified time, or are they stopping because a scheduled activity takes priority?
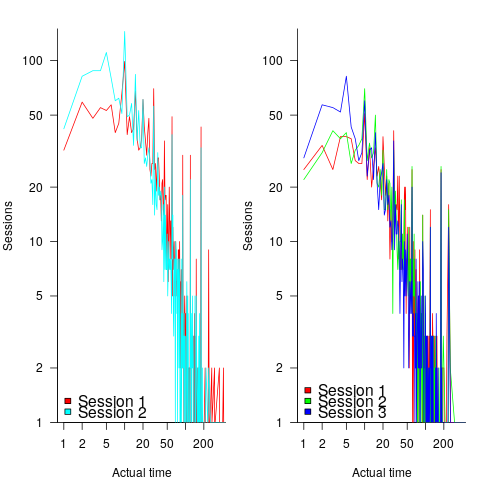
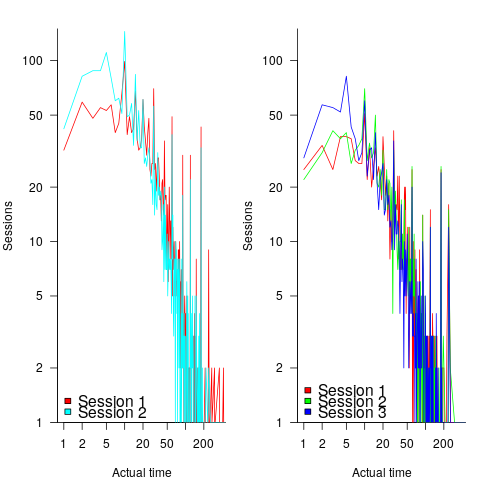
The plot below shows the number of times (y-axis) work on a task stopped on a given minute past the hour (x-axis), for 16 different software projects (project number in blue, with top 10 numbers in red, code+data):

Some projects have peaks at 50, 55, or thereabouts. Perhaps people are stopping because they have a meeting to attend, and a peak is visible because the project had lots of meetings, or no peak was visible because the project had few meetings. Some projects have a peak at 28 or 29, which might be some kind of time synchronization issue.
Is it possible to analyze the distribution of end minutes to reasonably infer developer project behavior, e.g., Parkinson’s law, striving to finish by a given time, or just not watching the clock?
An expected distribution pattern for both Parkinson’s law, and striving to complete, is a sharp decline of work stops after a reference time, e.g., end of an hour (this pattern is present in around ten of the projects plotted). A sharp increase in work stops prior to a reference time could also apply for both behaviors; stopping to switch to other work adds ‘noise’ to the distribution.
The CESAW data is organized by project, not developer, i.e., it does not list everything a developer did during the day. It is possible that end-of-hour work stops are driven by the need to synchronize with non-project activities, i.e., no Parkinson’s law or striving to complete.
In practice, some developers may sometimes follow Parkinson’s law, other times strive to complete, and other times not watch the clock. If models capable of separating out the behaviors were available, they might only be viable at the individual level.
Stop time equals start time plus work duration. If people choose a round number for the amount of work time, there is likely to be some correlation between start/end minutes past the hour. The plot below shows heat maps for start fraction of hour (y-axis) against end fraction of hour (x-axis) for four projects (code+data):
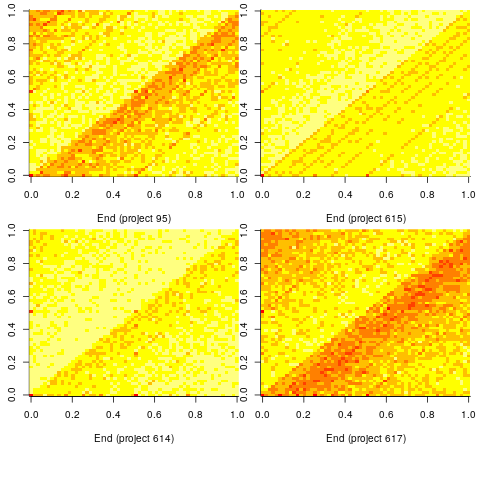
Work durations that are exact multiples of an hour appear along the main diagonal, with zero/zero being the most common start/end pair (at 4% over all projects, with 0.02% expected for random start/end times). Other diagonal lines come from work durations that include a fraction of an hour, e.g., 30-minutes and 20-minutes.
For most work periods, the start minute occurs before the end minute, i.e., the work period does not cross an hour boundary.
What can be learned from this analysis?
The main takeaway is that there is a small bias for work start/end times to occur on the hour or half-hour, and other activities (e.g., meetings) cause ongoing work to be interrupted. Not exactly news.
More interesting ideas and suggestions welcome.

 ) (
) (

 ) (
) (