Derek Jones from The Shape of Code
How long will it take to compile a source file?
When computers were a lot slower than they are today, this question was of general interest. Job scheduling is more effective when reliable runtime estimates are available, and developers want to know if there is enough time to get a coffee before the compile finishes.
An embarrassing fact about compile time performance, used to be that a large percentage of compile time was spent doing lexical analysis [“The cost of lexical analysis”, I cannot find an online copy]. Why was this embarrassing? Compiler writers like to boast about all the fancy optimizations their compiler does; but doing fancy stuff consumes lots of resources, so why were compilers spending so much of their time doing simple things like lexical analysis? The reality was that fancy compiler optimizations were not commercially viable until developer computers contained tens of megabytes of memory, i.e., very few pre-1990 compilers did any real optimization (people are still fussing over lexer performance).
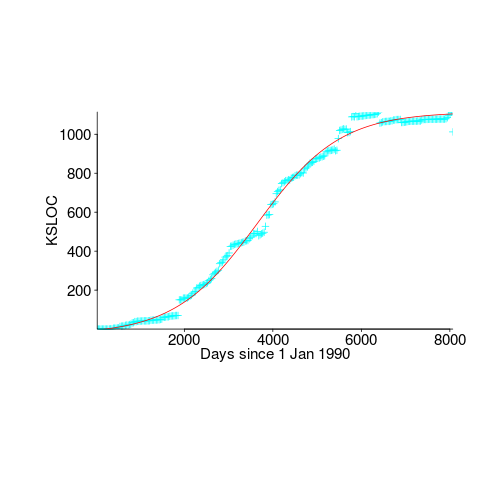
An analysis of the data in Captain Dennis Miller’s Masters thesis (late Rome period), finds compile time is proportional to the square root of the number of tokens in the source (code+data); more complicated models are a slightly better fit. Where did square root come from? I expected a linear relationship, but would be willing to go with log. The measurements are from Ada compilers in the mid 1980s. I know several people who worked on Ada compilers during that time, and they were implementing the latest fancy optimizations (Ada was going to be the next big thing and the venture capital was flowing; big companies, with big computers were going to be paying lots of money to use Ada, but then microcomputers came along). I think that square root is driven by OS resource limitations, the compilers are using lots of memory and a noticeable amount of time is spent swapping.
So computers got a lot faster and people lost interest in estimates of how long it would take to compile individual files. I have not seen any interest in predicting how long it would take to compile whole projects (just complaints about how long it takes). There has been some work on progress indicators, updated as compilation progresses, which is a step in the right direction. Perhaps somebody has recorded compile time information and thrown machine learning at it; I usually ignore machine learning papers applied to software engineering and perhaps I have missed something. Pointers to project compile time prediction work welcome.
Then along came just-in-time compilation. Now people want to estimate how long it will take to generate machine code from some intermediate form, that is being interpreted.
The plot below (thanks to Rafael Auler for kindly supplying the data from his paper) shows the time taken to generate code from functions containing a given number of LLVM instructions (an intermediate code), at optimization level O3. The red line is a regression fit to one of the ‘arms’ and shows constant time for less than 100’ish instructions and then a linear relationship. I have no idea why the time is roughly constant for a large number of functions.
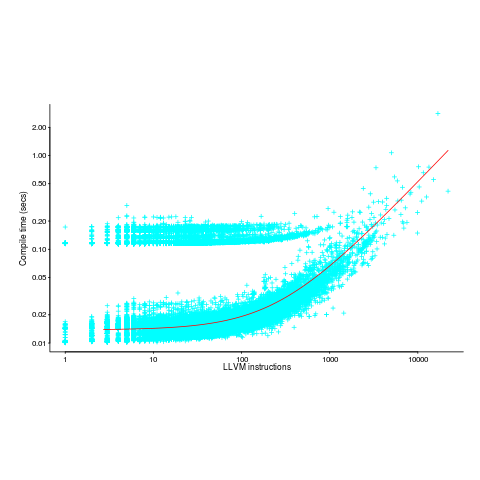
There is a lot of variation for function containing the same number of instructions. This is to be expected when lots of different optimizations are being tried; sometimes a function will contain lots of the kind of code that a particular optimization spends lot of times process and sometimes the code will not contain anything interesting (i.e., no optimizations are found).