Derek Jones from The Shape of Code
What is the skill difference between professional developers and newly minted computer science graduates?
Practice, e.g., 4,000 vs. 400 hours
People get better with practice, and after two years (around 4,000 hours) a professional developer will have had at least an order of magnitude more practice than most students; not just more practice, but advice and feedback from experienced developers. Most of these 4,000 hours are probably not the deliberate practice of 10,000 hours fame.
It’s understandable that graduates with a computing degree consider themselves to be proficient software developers; this opinion is based on personal experience (i.e., working with other students like themselves), and not having spent time working with professional developers. It’s not a joke that a surprising number of academics don’t appreciate the student/professional difference, the problem is that some academics only ever get to see a limit range of software development expertise (it’s a question of incentives).
Surveys of student study time have found that for Computer science, around 50% of students spend 11 hours or more, per week, in taught study and another 11 hours or more doing independent learning; let’s take 11 hours per week as the mean, and 30 academic weeks in a year. How much of the 330 hours per year of independent learning time is spent creating software (that’s 1,000 hours over a three-year degree, assuming that any programming is required)? I have no idea, and picked 40% because it matched up with 4,000.
Based on my experience with recent graduates, 400 hours sounds high (I have no idea whether an average student spends 4-hours per week doing programming assignments). While a rare few are excellent, most are hopeless. Perhaps the few hours per week nature of their coding means that they are constantly relearning, or perhaps they are just cutting and pasting code from the Internet.
Most graduates start their careers working in industry (around 50% of comp sci/maths graduates work in an ICT profession; UK higher-education data), which means that those working in industry are ideally placed to compare the skills of recent graduates and professional developers. Professional developers have first-hand experience of their novice-level ability. This is not a criticism of computing degrees; there are only so many hours in a day and lots of non-programming material to teach.
Many software developers working in industry don’t have a computing related degree (I don’t). Lots of non-computing STEM degrees give students the option of learning to program (I had to learn FORTRAN, no option). I don’t have any data on the percentage of software developers with a computing related degree, and neither do I have any data on the average number of hours non-computing STEM students spend on programming; I’ve cosen 40 hours to flow with the sequence of 4’s (some non-computing STEM students spend a lot more than 400 hours programming; I certainly did). The fact that industry hires a non-trivial number of non-computing STEM graduates as software developers suggests that, for practical purposes, there is not a lot of difference between 400 and 40 hours of practice; some companies will take somebody who shows potential, but no existing coding knowledge, and teach them to program.
Many of those who apply for a job that involves software development never get past the initial screening; something like 80% of people applying for a job that specifies the ability to code, cannot code. This figure is based on various conversations I have had with people about their company’s developer recruitment experiences; it is not backed up with recorded data.
Some of the factors leading to this surprisingly high value include: people attracted by the salary deciding to apply regardless, graduates with a computing degree that did not require any programming (there is customer demand for computing degrees, and many people find programming is just too hard for them to handle, so universities offer computing degrees where programming is optional), concentration of the pool of applicants, because those that can code exit the applicant pool, leaving behind those that cannot program (who keep on applying).
Apologies to regular readers for yet another post on professional developers vs. students, but I keep getting asked about this issue.
 , where:
, where:  is the time taken to do the task,
is the time taken to do the task, is some measure of practice (such as the number of times the subject has performed the task), and
is some measure of practice (such as the number of times the subject has performed the task), and  ,
,  , and
, and  are constants fitted to the data.
are constants fitted to the data. . The power law appeared to be the result of aggregating the exponential response performance of multiple subjects; oops.
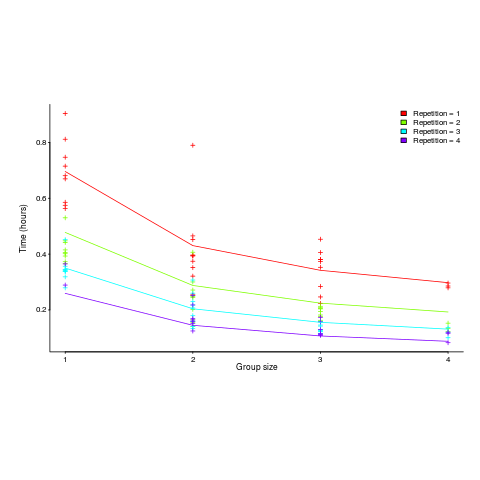
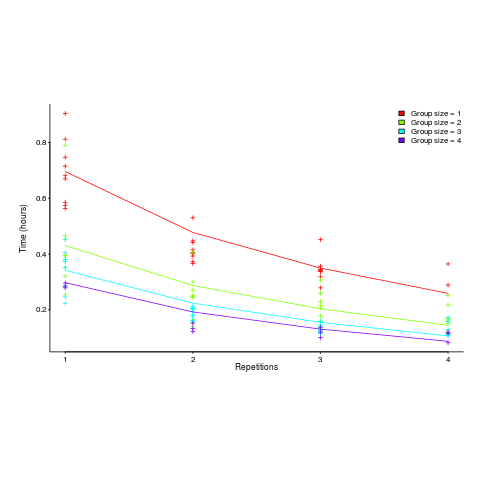
. The power law appeared to be the result of aggregating the exponential response performance of multiple subjects; oops.") applies, but the division by group-size was found by suck-it-and-see (in another post I found that
applies, but the division by group-size was found by suck-it-and-see (in another post I found that ![time = 0.16+ 0.53/{group size} - log(repetitions)*[0.1 + {0.22}/{group size}]](http://shape-of-code.coding-guidelines.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_980.5_b0d171bba046801a68ce5dc8ae1d6115.png "time = 0.16+ 0.53/{group size} - log(repetitions)*[0.1 + {0.22}/{group size}]")