Derek Jones from The Shape of Code
Estimating how long it will take to complete a task is hard work, and the most common motivation for this work comes from external factors, e.g., the boss, or a potential client asks for an estimate to do a job.
People also make estimates for their own use, e.g., when planning work for the day. Various processes and techniques have been created to help structure the estimation process; for developers there is the Personal Software Process, and specifically for time estimation (but not developer specific), there is the Pomodoro Technique.
I met Renzo Borgatti at the first talk I gave on the SiP dataset (Renzo is the organizer of the Papers We Love meetup). After the talk, Renzo told me about his use of the Pomodoro Technique, and how he had 10-years worth of task estimates; wow, I was very interested. What happened next, and a work-in-progress analysis (plus data and R scripts) of the data can be found in the Renzo Pomodoro dataset repo.
The analysis progressed in fits and starts; like me Renzo is working on a book, and is very busy. The work-in-progress pdf is reasonably consistent.
I had never seen a dataset of estimates made for personal use, and had not read about the analysis of such data. When estimates are made for consumption by others, the motives involved in making the estimate can have a big impact on the values chosen, e.g., underestimating to win a bid, or overestimating to impress the boss by completing a task under budget. Is a personal estimate motive free? The following plot led me to ask Renzo if he was superstitious (in not liking odd numbers).
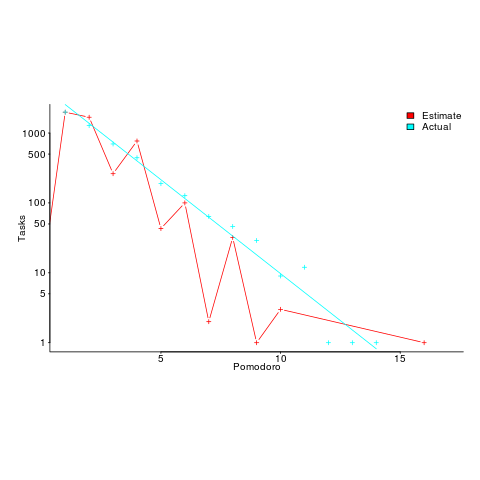
The plot shows the number of tasks for which there are a given number of estimates and actuals (measured in Pomodoros, i.e., units of 25 minutes). Most tasks are estimated to require one Pomodoro, and actually require this amount of effort.
Renzo educated me about the details of the Pomodoro technique, e.g., there is a 15-30 minute break after every four Pomodoros. Did this mean that estimates of three Pomodoros were less common because the need for a break was causing Renzo to subconsciously select an estimate of two or four Pomodoro? I am not brave enough to venture an opinion about what is going on in Renzo’s head.
Each estimated task has an associated tag name (sometimes two), which classifies the work involved, e.g., @planning. In the task information these tags have the form @word; I refer to them as at-words. The following plot is very interesting; it shows the date of use of each at-word, over time (ordered by first use of the at-word).
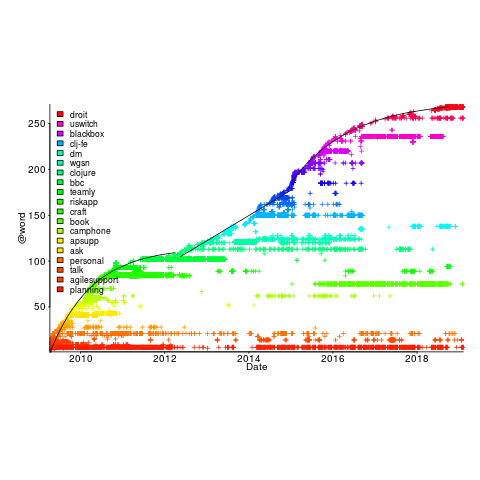
The first and third black lines are fitted regression models of the form  , where:
, where:  is a constant and
is a constant and  is the number of days since the start of the interval fitted. The second (middle) black line is a fitted straight line.
is the number of days since the start of the interval fitted. The second (middle) black line is a fitted straight line.
The slow down in the growth of new at-words suggests (at least to me) a period of time working in the same application domain (which involves a fixed number of distinct activities, that are ‘discovered’ by Renzo over time). More discussion with Renzo is needed to see if we can tie this down to what he was working on at the time.
I have looked for various other patterns and associations, involving at-words, but have not found any (but I did learn some new sequence analysis techniques, and associated R packages).
The data is now out there. What patterns and associations can you find?
Renzo tells me that there is a community of people using the Pomodoro technique. I’m hoping that others users of this technique, involved in software development, have recorded their tasks over a long period (I don’t think I could keep it up for longer than a week).
Perhaps there are PSP followers out there with data…
I offer to do a free analysis of software engineering data, provided I can make data public (in anonymized form). Do get in touch.