Derek Jones from The Shape of Code
People tend to use round numbers. When asked the time, the response is often rounded to the nearest 5-minute or 15-minute value, even when using a digital watch; the speaker is using what they consider to be a relevant level of accuracy.
When estimating how long it will take to perform a task, developers tend to use round numbers (based on three datasets). Giving what appears to be an overly precise value could be taken as communicating extra information, e.g., an estimate of 1-hr 3-minutes communicates a high degree of certainty (or incompetence, or making a joke). If the consumer of the estimate is working in round numbers, it makes sense to give a round number estimate.
Three large software related effort estimation datasets are now available: the SiP data contains estimates made by many people, the Renzo Pomodoro data is one person’s estimates, and now we have the Brightsquid data (via the paper “Utilizing product usage data for requirements evaluation” by Hemmati, Didar Al Alam and Carlson; I cannot find an online pdf at the moment).
The plot below shows the total number of tasks (out of the 1,945 tasks in the Brightsquid data) for which a given estimate value was recorded; peak values shown in red (code+data):
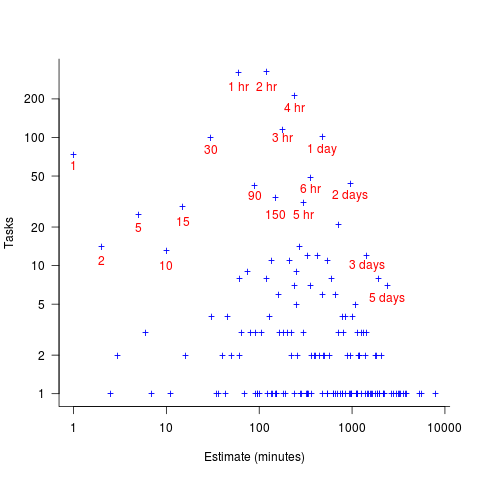
Why are there estimates for tasks taking less than 30 minutes? What are those 1 minute tasks (are they typos, where the second digit was omitted and the person involved simply create a new estimate without deleting the original)? How many of those estimate values appearing once are really typos, e.g., 39 instead of 30? Does the task logging system used require an estimate before anything can be done? Unfortunately I don’t have access to the people involved. It does look like this data needs some cleaning.
There are relatively few 7-hour estimates, but lots for 8-hours. I’m assuming the company works an 8-hour day (the peak at 4-hours, rather than three, adds weight to this assumption).