Derek Jones from The Shape of Code
Code review is often discussed from the perspective of changes to a single file. In practice, code review often involves multiple files (or at least pull-based reviews do), which begs the question: Do people invest less effort reviewing files appearing later?
TLDR: The number of review comments decreases for successive files in the pull request; by around 16% per file.
The paper First Come First Served: The Impact of File Position on Code Review extracted and analysed 219,476 pull requests from 138 Java projects on Github. They also ran an experiment which asked subjects to review two files, each containing a seeded coding mistake. The paper is relatively short and omits a lot of details; I’m guessing this is due to the page limit of a conference paper.
The plot below shows the number of pull requests containing a given number of files. The colored lines indicate the total number of code review comments associated with a given pull request, with the red dots showing the 69% of pull requests that did not receive any review comments (code+data):
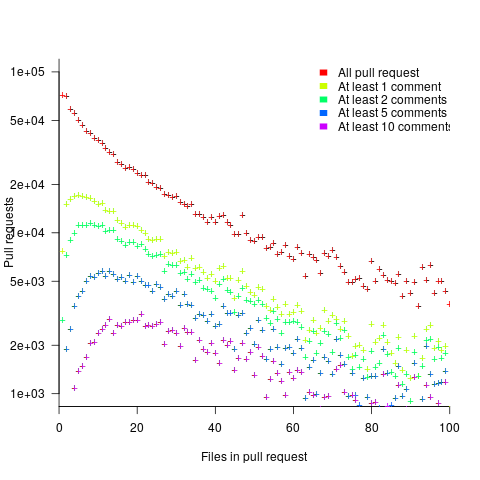
Many factors could influence the number of comments associated with a pull request; for instance, the number of people commenting, the amount of changed code, whether the code is a test case, and the number of files already reviewed (all items which happen to be present in the available data).
One factor for which information is not present in the data is social loafing, where people exert less effort when they are part of a larger group; or at least I did not find a way of easily estimating this factor.
The best model I could fit to all pull requests containing less than 10 files, and having a total of at least one comment, explained 36% of the variance present, which is not great, but something to talk about. There was a 16% decline in comments for successive files reviewed, test cases had 50% fewer comments, and there was some percentage increase with lines added; number of comments increased by a factor of 2.4 per additional commenter (is this due to importance of the file being reviewed, with importance being a metric not present in the data).
The model does not include information available in the data, such as file contents (e.g., Java, C++, configuration file, etc), and there may be correlated effects I have not taken into account. Consequently, I view the model as a rough guide.
Is the impact of file order on number of comments a side effect of some unrelated process? One way of showing a causal connection is to run an experiment.
The experiment run by the authors involved two files, each containing one seeded coding mistake. The 102 subjects were asked to review the two files, with file order randomly selected. The experiment looks well-structured and thought through (many are not), but the analysis of the results is confused.
The good news is that the seeded coding mistake in the first file was much more likely to be detected than the mistake in the second file, and years of Java programming experience also had an impact (appearing first had the same impact as three years of Java experience). The bad news is that the model (a random effect model using a logistic equation) explains almost none of the variance in the data, i.e., these effects are tiny compared to whatever other factors are involved; see code+data.
What other factors might be involved?
Most experiments show a learning effect, in that subject performance improves as they perform more tasks. Having subjects review many pairs of files would enable this effect to be taken into account. Also, reviewing multiple pairs would reduce the impact of random goings-on during the review process.
The identity of the seeded mistake did not have a significant impact on the model.
Review comments are an important issue which is amenable to practical experimental investigation. I hope that the researchers run more experiments on this issue.