Derek Jones from The Shape of Code
Most developers think …
Most editors …
Most programs …
Linguistically most is a quantifier (it’s a proportional quantifier); a word-phrase used to convey information about the number of something, e.g., all, any, lots of, more than half, most, some.
Studies of most have often compared and contrasted it with the phrase more than half; findings include: most has an upper bound (i.e., not all), and more than half has a lower bound (but no upper bound).
A corpus analysis of most (432,830 occurrences) and more than half (4,857 occurrences) found noticeable usage differences. Perhaps the study’s most interesting finding, from a software engineering perspective, was that most tended to be applied to vague and uncountable domains (i.e., there was no expectation that the population of items could be counted), while uses of more than half almost always had a ‘survey results’ interpretation (e.g., supporting data cited as collaboration for 80% of occurrences; uses of most cited data for 19% of occurrences).
Readers will be familiar with software related claims containing the most qualifier, which are actually opinions that are not grounded in substantive numeric data.
When most is used in a numeric based context, what percentage (of a population) is considered to be most (of the population)?
When deciding how to describe a proportion, a writer has the choice of using more than half, most, or another qualifier. Corpus based studies find that the distribution of most has a higher average percentage value than more than half (both are left skewed, with most peaking around 80-85%).
When asked to decide whether a phrase using a qualifier is true/false, with respect to background information (e.g., Given that 55% of the birlers are enciad, is it true that: Most of the birlers are enciad?), do people treat most and more than half as being equivalent?
A study by Denić and Szymanik addressed this question. Subjects (200 took part, with results from 30 were excluded for various reasons) saw a statement involving a made-up object and verb, such as: “55% of the birlers are enciad.” They then saw a sentence containing either most or more than half, that was either upward-entailing (e.g., “More than half of the birlers are enciad.”), or downward-entailing (e.g., “It is not the case that more than half of the birlers are enciad.”); most/more than half and upward/downward entailing creates four possible kinds of sentence. Subjects were asked to respond true/false.
The percentage appearing in the first sentence of the two seen by subjects varied, e.g., “44% of the tiklets are hullaw.”, “12% of the puggles are entand.”, “68% of the plipers are sesare.” The percentage boundary where each subjects’ true/false answer switched was calculated (i.e., the mean of the percentages present in the questions’ each side of true/false boundary; often these values were 46% and 52%, whose average is 49; this is an artefact of the question wording).
The plot below shows the number of subjects whose true/false boundary occurred at a given percentage (code+data):
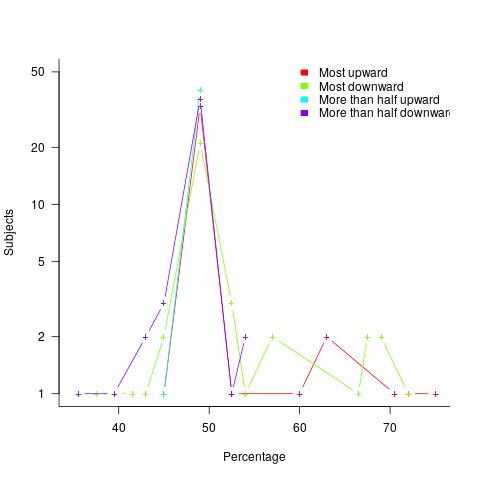
When asked, the majority of subjects had a 50% boundary for most/more than half+upward/downward. A downward entailment causes some subjects to lower their 50% boundary.
So now we know (subject to replication). Most people are likely to agree that 50% is the boundary for most/more than half, but some people think that the boundary percentage is higher for most.
When asked to write a sentence, percentages above 50% attract more mosts than more than halfs.
Most is preferred when discussing vague and uncountable domains; more than half is used when data is involved.