Derek Jones from The Shape of Code
How good a job does a test suite do in detecting coding mistakes in the program it tests?
Mutation testing provides one answer to this question. The idea behind mutation testing is to make a small change to the source code of the program under test (i.e., introduce a coding mistake), and then run the test suite through the mutated program (ideally one or more tests fail, as-in different behavior should be detected); rinse and repeat. The mutation score is the percentage of mutated programs that cause a test failure.
While Mutation testing is 50-years old this year (although the seminal paper/a> did not get published until 1978), the computing resources needed to research it did not start to become widely available until the late 1980s. From then, Until fuzz testing came along, mutation testing was probably the most popular technique studied by testing researchers. A collected bibliography of mutation testing lists 417 papers and 16+ PhD thesis (up to May 2014).
Mutation testing has not been taken up by industry because it tells managers what they already know, i.e., their test suite is not very good at finding coding mistakes.
Researchers concluded that the reason industry had not adopted mutation testing was that it was too resource intensive (i.e., mutate, compile, build, and run tests requires successively more resources). If mutation testing was less resource intensive, then industry would use it (to find out faster what they already knew).
Creating a code mutant is not itself resource intensive, e.g., randomly pick a point in the source and make a random change. However, the mutated source may not compile, or the resulting mutant may be equivalent to one created previously (e.g., the optimised compiled code is identical), or the program takes ages to compile and build; techniques for reducing the build overhead include mutating the compiler intermediate form and mutating the program executable.
Some changes to the source are more likely to be detected by a test suite than others, e.g., replacing <= by > is more likely to be detected than replacing it by < or ==. Various techniques for context dependent mutations have been proposed, e.g., handling of conditionals.
While mutation researchers were being ignored by industry, another group of researchers were listening to industry's problems with testing; automatic test case generation took off. How might different test case generators be compared? Mutation testing offers a means of evaluating the performance of tools arrived on the scene (in practice, many researchers and tool vendors cite statement or block coverage numbers).
Perhaps industry might have to start showing some interest in mutation testing.
A fundamental concern is the extent to which mutation operators modify source in a way that is representative of the kinds of mistakes made by programmers.
The competent programmer hypothesis is often cited, by researchers, as the answer to this question. The hypothesis is that competent programmers write code/programs that is close to correct; the implied conclusion being that mutations, which are small changes, must therefore be like programmer mistakes (the citation often given as the source of this hypothesis discusses data selection during testing, but does mention the term competent programmer).
Until a few years ago, most analysis of fixes of reported faults looked at what coding constructs were involved in correcting the source code, e.g., 296 mistakes in TeX reported by Knuth. This information can be used to generate a probability table for selecting when to mutate one token into another token.
Studies of where the source code was changed, to fix a reported fault, show that existing mutation operators are not representative of a large percentage of existing coding mistakes; for instance, around 60% of 290 source code fixes to AspectJ involved more than one line (mutations usually involve a single line of source {because they operate on single statements and most statements occupy one line}), another study investigating many more fixes found only 10% of fixes involved one line, and similar findings for a study of C, Java, Python, and Haskell (a working link to the data, which is a bit of a mess).
These studies, which investigated the location of all the source code that needs to be changed, to fix a mistake, show that existing mutation operators are not representative of most human coding mistakes. To become representative, mutation operators need to be capable of making coupled changes across multiple lines/functions/methods and even files.
While arguments over the validity of the competent programmer hypothesis rumble on, the need for multi-line changes remains.
Given the lack of any major use-cases for mutation testing, it does not look like it is worth investing lots of resources on this topic. Researchers who have spent a large chunk of their career working on mutation testing will probably argue that you never know what use-cases might crop up in the future. In practice, mutation research will probably fade away because something new and more interesting has come along, i.e., fuzz testing.
There will always be niche use-cases for mutation. For instance, how likely is it that a random change to the source of a formal proof will go unnoticed by its associated proof checker (i.e., the proof checking tool output remains unchanged)?
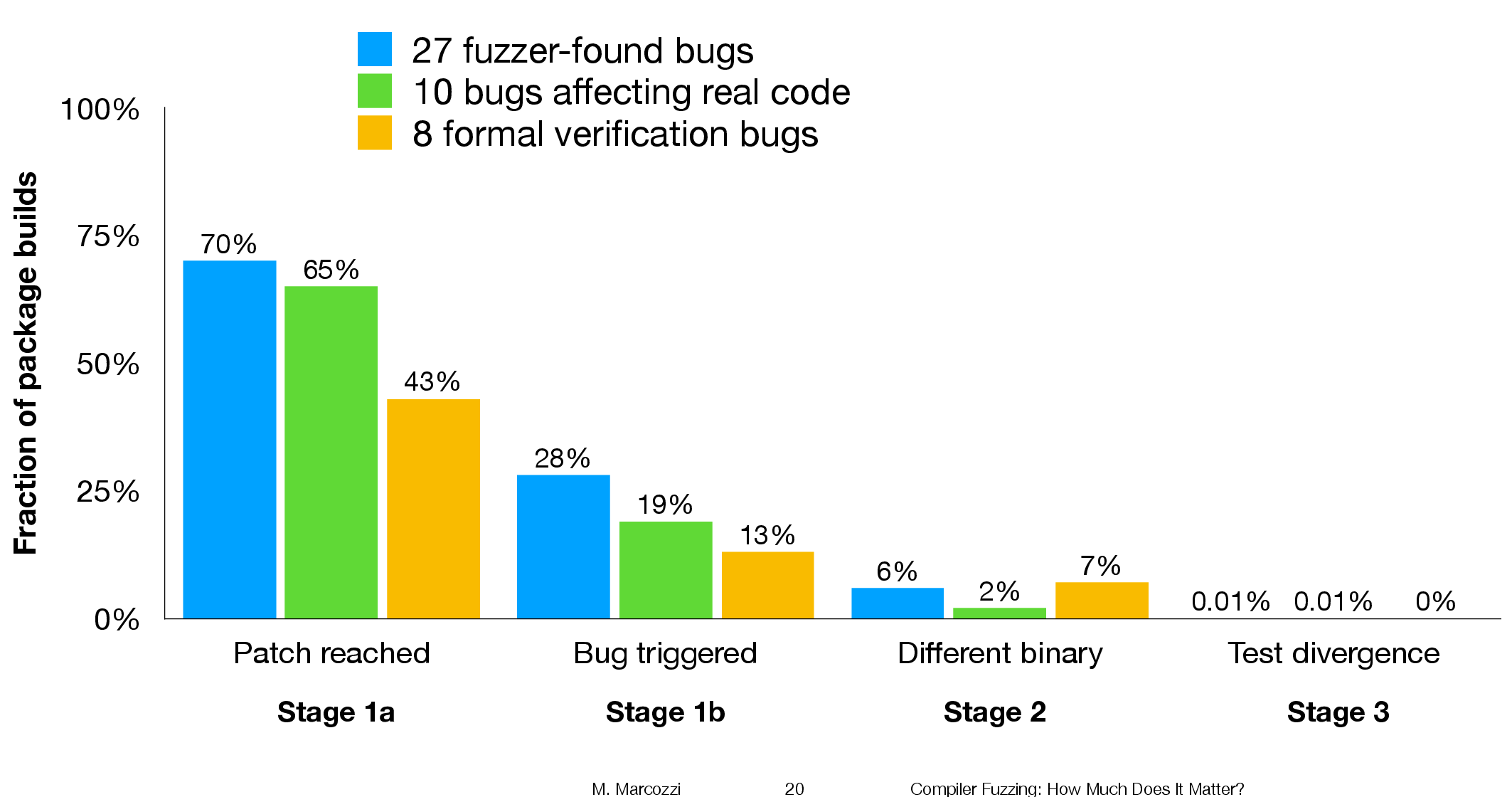
A study based on mutating the source of Coq verification projects found that 7% of mutations had no impact on the results.
 (
(
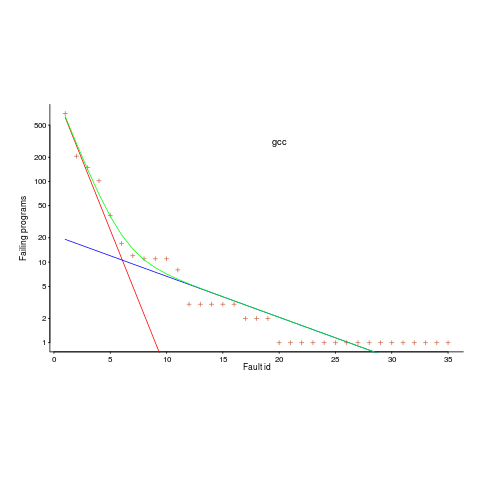
 is that one exponential is driven by the presence of faults in the code and the other exponential is driven by the way in which Csmith meanders over the possible C source.
is that one exponential is driven by the presence of faults in the code and the other exponential is driven by the way in which Csmith meanders over the possible C source.