Derek Jones from The Shape of Code
Today, I am thinking of investing 1-hour of effort adding more comments to my code; how much time must this investment save me X-months from now, for today’s 1-hour investment to be worthwhile?
Obviously, I must save at least 1-hour. But, the purpose of making an investment is to receive a greater amount at a later time; ‘paying’ 1-hour to get back 1-hour is a poor investment (unless I have nothing else to do today, and I’m likely to be busy in the coming months).
The usual economic’s based answer is based on compound interest, the technique your bank uses to calculate how much you owe them (or perhaps they owe you), i.e., the expected future value grows exponentially at some interest rate.
Psychologists were surprised to find that people don’t estimate future value the way economists do. Hyperbolic discounting provides a good match to the data from experiments that asked subjects to value future payoffs. The form of the equation used by economists is:  , while hyperbolic discounting has the form
, while hyperbolic discounting has the form  , where:
, where:  is a constant, and
is a constant, and  the period of time.
the period of time.
The simple economic approach does not explicitly include the risk that one of the parties involved may cease to exist. Including risk is non-trivial, banks handle the risk that you might disappear by asking for collateral, or adding something to the interest rate charged.
The fact that humans, and some other animals, have been found to use hyperbolic discounting suggests that evolution has found this approach, to discounting time, increases the likelihood of genes being passed on to the next generation. A bird in the hand is worth two in the bush.
How do software developers discount investment in software engineering projects?
The paper Temporal Discounting in Technical Debt: How do Software Practitioners Discount the Future? describes a study that specifies a decision that has to be made and two options, as follows:
“You are managing an N-years project. You are ahead of schedule in the current iteration. You have to decide between two options on how to spend our upcoming week. Fill in the blank to indicate the least amount of time that would make you prefer Option 2 over Option 1.
- Option 1: Implement a feature that is in the project backlog, scheduled for the next iteration. (five person days of effort).
- Option 2: Integrate a new library (five person days effort) that adds no new functionality but has a 60% chance of saving you person days of effort over the duration of the project (with a 40% chance that the library will not result in those savings).
”
Subjects are then asked six questions, each having the following form (for various time frames):
“For a project time frame of 1 year, what is the smallest number of days that would make you prefer Option 2? ___”
The experiment is run twice, using professional developers from two companies, C1 and C2 (23 and 10 subjects, respectively), and the data is available for download 
The following plot shows normalised values given by some of the subjects from company C1, for the various time periods used. On a log scale, values estimated using the economists exponential approach would form a straight line (e.g., close to the first five points of subject M, bottom right), and values estimated using the hyperbolic approach would have the concave form seen for subject C (top middle) (code+data).
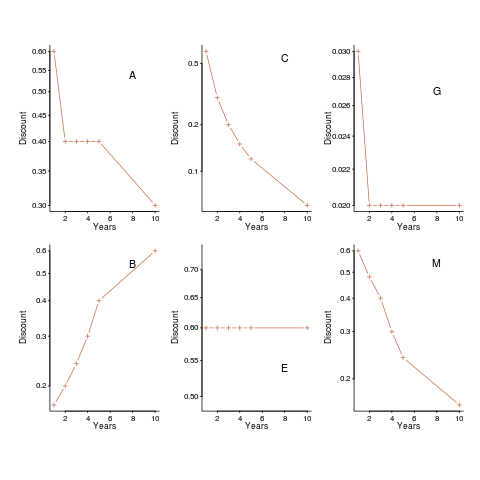
Subject B is asking for less, not more, over a longer time period (several other subjects have the same pattern of response). Why did Subject E (and most of subject G’s responses) not vary with time? Perhaps they were tired and were not willing to think hard about the problem, or perhaps they did not think the answer made much difference. The subjects from company C2 showed a greater amount of variety. Company C1 had some involvement with financial applications, while company C2 was involved in simulations. Did this domain knowledge spill over into company C1’s developers being more likely to give roughly consistent answers?
The experiment was run online, rather than an experimenter being in the room with subjects. It is possible that subjects would have invested more effort if a more formal setting, with an experimenter who had made the effort to be present. Also, if an experimenter had been present, it would have been possible to ask question to clarify any issues.
Both exponential and hyperbolic equations can be fitted to the data, but given the diversity of answers, it is difficult to put any weight in either regression model. Some subjects clearly gave responses fitting a hyperbolic equation, while others gave responses fitted approximately well by either approach, and other subjects used. It was possible to fit the combined data from all of company C1 subjects to a single hyperbolic equation model (the most significant between subject variation was the value of the intercept); no such luck with the data from company C2.
I’m very please to see there has been a replication of this study, but the current version of the paper is a jumble of ideas, and is thin on experimental procedure. I’m sure it will improve.
What do we learn from this study? Perhaps that developers need to learn something about calculating expected future payoffs.