Derek Jones from The Shape of Code
If 100 people estimate the time needed to implement a feature, in software, what is the expected variability in the estimates?
Studies of multiple implementations of the same specification suggest that standard deviation of the mean number of lines across implementations is 25% of the mean (based on data from 10 sets of multiple implementations, of various sizes).
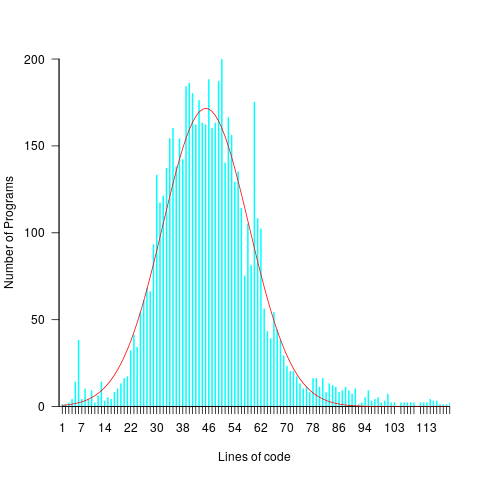
The plot below shows lines of code against the number of programs (implementing the 3n+1 problem) containing that many lines (code and data):
Might any variability in the estimates for task implementation be the result of individuals estimating their own performance (which is variable)?
To the extent that an estimate is based on a person’s implementation experience, a developer’s past performance will have some impact on their estimate. However, studies have found a great deal of variability between individual estimates and their corresponding performance.
One study asked 14 companies to bid on implementing a system (four were eventually chosen to implement it; see figure 5.2 in my book). The estimated elapsed time varied by a factor of ten. Until the last week this was the only study of this question for which the data was available (and may have been the only such study).
A study by Alhamed and Storer investigated crowd-sourcing of effort estimates, structured by use of planning poker. The crowd were workers on Amazon’s Mechanical Turk, and the tasks estimated came from the issue trackers of JBoss, Apache and Spring Integration (using issues that had been annotated with an estimate and actual time, along with what was considered sufficient detail to make an estimate). An initial set of 419 issues were whittled down to 30, which were made available, one at a time, as a Mechanical Turk task (i.e., only one issue was available to be estimated at any time).
Worker estimates were given using a time-based category (i.e., the values 1, 4, 8, 20, 40, 80), with each value representing a unit of actual time (i.e., one hour, half-day, day, half-week, week and two weeks, respectively).
Analysis of the results from a pilot study were used to build a model that detected estimates considered to be low quality, e.g., providing a poor justification for the estimate. These were excluded from any subsequent iterations.
Of the 506 estimates made, 321 passed the quality check.
Planning poker is an iterative process, with those making estimates in later rounds seeing estimates made in earlier rounds. So estimates made in later rounds are expected to have some correlation with earlier estimates.
Of the 321 quality check passing estimates, 153 were made in the first-round. Most of the 30 issues have 5 first-round estimates each, one has 4 and two have 6.
Workers have to pick one of five possible value as their estimate, with these values being roughly linear on a logarithmic scale, i.e., it is not possible to select an estimate from many possible large values, small values, or intermediate values. Unless most workers pick the same value, the standard deviation is likely to be large. Taking the logarithm of the estimate maps it to a linear scale, and the plot below shows the mean and standard deviation of the log of the estimates for each issue made during the first-round (code+data):

The wide spread in the standard deviations across a spread of mean values may be due to small sample size, or it may be real. The only way to find out is to rerun with larger sample sizes per issue.
Now it has been done once, this study needs to be run lots of times to measure the factors involved in the variability of developer estimates. What would be the impact of asking workers to make hourly estimates (they would not be anchored by experimenter specified values), or shifting the numeric values used for the categories (which probably have an anchoring effect)? Asking for an estimate to fix an issue in a large software system introduces the unknown of all kinds of dependencies, would estimates provided by workers who are already familiar with a project be consistently shifted up/down (compared to estimates made by those not familiar with the project)? The problem of unknown dependencies could be reduced by giving workers self-contained problems to estimate, e.g., the 3n+1 problem.
The crowdsourcing idea is interesting, but I don’t think it will scale, and I don’t see many companies making task specifications publicly available.
To mimic actual usage, research on planning poker (which appears to have non-trivial usage) needs to ensure that the people making the estimates are involved during all iterations. What is needed is a dataset of lots of planning poker estimates. Please let me know if you know of one.