Derek Jones from The Shape of Code
Over the last decade, testing compilers using automatically generated source code has been a popular research topic (for those working in the compiler field; Csmith kicked off this interest). Compilers are large complicated programs, and they will always contain mistakes that lead to faults being experienced. Previous posts of mine have raised two issues on the use of automatically generated tests: a financial issue (i.e., fixing reported faults costs money {most of the work on gcc and llvm is done by people working for large companies}, and is intended to benefit users not researchers seeking bragging rights for their latest paper), and applicability issue (i.e., human written code has particular characteristics and unless automatically generated code has very similar characteristics the mistakes it finds are unlikely to commonly occur in practice).
My claim that mistakes in compilers found by automatically generated code are unlikely to be the kind of mistakes that often lead to a fault in the compilation of human written code is based on the observations (I don’t have any experimental evidence): the characteristics of automatically generated source is very different from human written code (I know this from measurements of lots of code), and this difference results in parts of the compiler that are infrequently executed by human written code being more frequently executed (increasing the likelihood of a mistake being uncovered; an observation based on my years working on compilers).
An interesting new paper, Compiler Fuzzing: How Much Does It Matter?, investigated the extent to which fault experiences produced by automatically generated source are representative of fault experiences produced by human written code. The first author of the paper, Michaël Marcozzi, gave a talk about this work at the Papers We Love workshop last Sunday (videos available).
The question was attacked head on. The researchers instrumented the code in the LLVM compiler that was modified to fix 45 reported faults (27 from four fuzzing tools, 10 from human written code, and 8 from a formal verifier); the following is an example of instrumented code:
warn ("Fixing patch reached");
if (Not.isPowerOf2()) {
if (!(C-> getValue().isPowerOf2() // Check needed to fix fault
&& Not != C->getValue())) {
warn("Fault possibly triggered");
} else { /* CODE TRANSFORMATION */ } } // Original, unfixed code
The instrumented compiler was used to build 309 Debian packages (around 10 million lines of C/C++). The output from the builds were (possibly miscompiled) built versions of the packages, and log files (from which information could be extracted on the number of times the fixing patches were reached, and the number of cases where the check needed to fix the fault was triggered).
Each built package was then checked using its respective test suite; a package built from miscompiled code may successfully pass its test suite.
A bitwise compare was run on the program executables generated by the unfixed and fixed compilers.
The following (taken from Marcozzi’s slides) shows the percentage of packages where the fixing patch was reached during the build, the percentages of packages where code added to fix a fault was triggered, the percentage where a different binary was generated, and the percentages of packages where a failure was detected when running each package’s tests (0.01% is one failure):
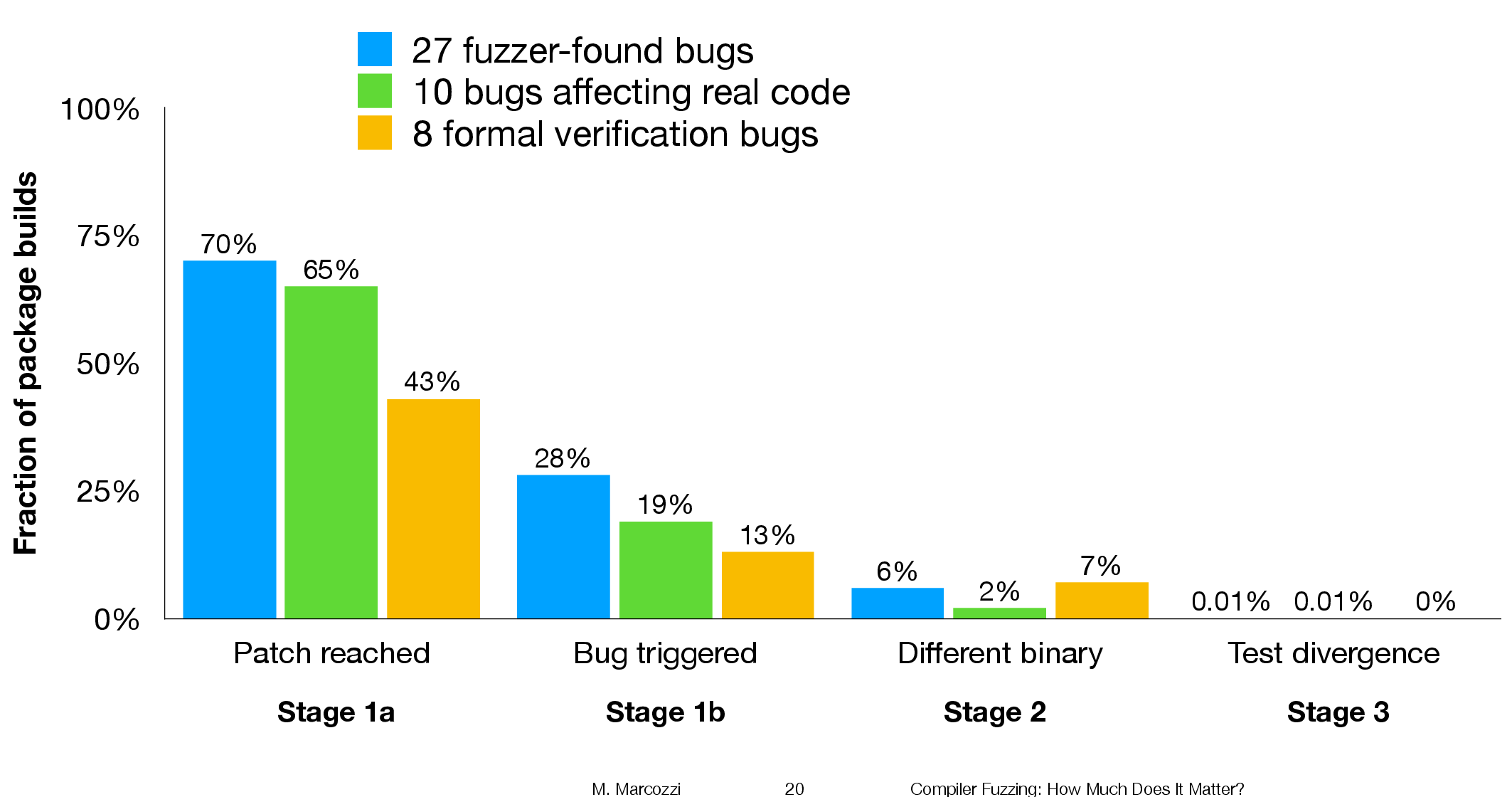
The takeaway from the above figure is that many packages are affected by the coding mistakes that have been fixed, but that most package test suites are not affected by the miscompilations.
To find out whether there is a difference, in terms of impact on Debian packages, between faults reported in human and automatically generated code, we need to compare number of occurrences of “Fault possibly triggered”. The table below shows the break-down by the detector of the coding mistake (i.e., Human and each of the automated tools used), and the number of fixed faults they contributed to the analysis.
Human, Csmith and EMI each contributed 10-faults to the analysis. The fixes for the 10-fault reports in human generated code were triggered 593 times when building the 309 Debian packages, while each of the 10 Csmith and EMI fixes were triggered 1,043 and 948 times respectively; a lot more than the Human triggers :-O. There are also a lot more bitwise compare differences for the non-Human fault-fixes.
Detector Faults Reached Triggered Bitwise-diff Tests failed
Human 10 1,990 593 56 1
Csmith 10 2,482 1,043 318 0
EMI 10 2,424 948 151 1
Orange 5 293 35 8 0
yarpgen 2 608 257 0 0
Alive 8 1,059 327 172 0
Is the difference due to a few packages being very different from the rest?
The table below breaks things down by each of the 10-reported faults from the three Detectors.
Ok, two Human fault-fix locations are never reached when compiling the Debian packages (which is a bit odd), but when the locations are reached they are just not triggering the fault conditions as often as the automatic cases.
Detector Reached Triggered
Human
300 278
301 0
305 0
0 0
0 0
133 44
286 231
229 0
259 40
77 0
Csmith
306 2
301 118
297 291
284 1
143 6
291 286
125 125
245 3
285 16
205 205
EMI
130 0
307 221
302 195
281 32
175 5
122 0
300 295
297 215
306 191
287 10
It looks like I am not only wrong, but that fault experiences from automatically generated source are more (not less) likely to occur in human written code (than fault experiences produced by human written code).
This is odd. At best I would expect fault experiences from human and automatically generated code to have the same characteristics.
Ideas and suggestions welcome.