Derek Jones from The Shape of Code
A programming language is sometimes described as being similar to another, more wide known, language.
How might language similarity be measured?
Biologists ask a very similar question, and research goes back several hundred years; phenetics (also known as taximetrics) attempts to classify organisms based on overall similarity of observable traits.
One answer to this question is based on distance matrices.
The process starts by flagging the presence/absence of each observed trait. Taking language keywords (or reserved words) as an example, we have (for a subset of C, Fortran, and OCaml):
if then function for do dimension object
C 1 1 0 1 1 0 0
Fortran 1 0 1 0 1 1 0
OCaml 1 1 1 1 1 0 1
The distance between these languages is calculated by treating this keyword presence/absence information as an n-dimensional space, with each language occupying a point in this space. The following shows the Euclidean distance between pairs of languages (using the full dataset; code+data):
C Fortran OCaml
C 0 7.615773 8.717798
Fortran 7.615773 0 8.831761
OCaml 8.717798 8.831761 0
Algorithms are available to map these distance pairs into tree form; for biological organisms this is known as a phylogenetic tree. The plot below shows such a tree derived from the keywords supported by 21 languages (numbers explained below, code+data):
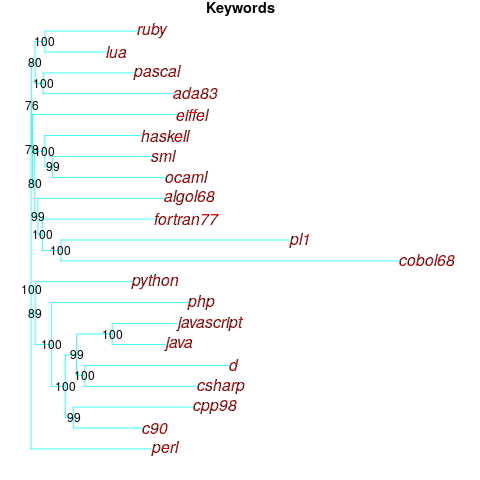
How confident should we be that this distance-based technique produced a robust result? For instance, would a small change to the set of keywords used by a particular language cause it to appear in a different branch of the tree?
The impact of small changes on the generated tree can be estimated using a bootstrap technique. The particular small-change algorithm used to estimate confidence levels for phylogenetic trees is not applicable for language keywords; genetic sequences contain multiple instances of four DNA bases, and can be sampled with replacement, while language keywords are a set of distinct items (i.e., cannot be sampled with replacement).
The bootstrap technique I used was: for each of the 21 languages in the data, was: add keywords to one language (the number added was 5% of the number of its existing keywords, randomly chosen from the set of all language keywords), calculate the distance matrix and build the corresponding tree, repeat 100 times. The 2,100 generated trees were then compared against the original tree, counting how many times each branch remained the same.
The numbers in the above plot show the percentage of generated trees where the same branching decision was made using the perturbed keyword data. The branching decisions all look very solid.
Can this keyword approach to language comparison be applied to all languages?
I think that most languages have some form of keywords. A few languages don’t use keywords (or reserved words), and there are some edge cases. Lisp doesn’t have any reserved words (they are functions), nor technically does Pl/1 in that the names of ‘word tokens’ can be defined as variables, and CHILL implementors have to choose between using Cobol or PL/1 syntax (giving CHILL two possible distinct sets of keywords).
To what extent are a language’s keywords representative of the language, compared to other languages?
One way to try and answer this question is to apply the distance/tree approach using other language traits; do the resulting trees have the same form as the keyword tree? The plot below shows the tree derived from the characters used to represent binary operators (code+data):

A few of the branching decisions look as-if they are likely to change, if there are changes to the keywords used by some languages, e.g., OCaml and Haskell.
Binary operators don’t just have a character representation, they can also have a precedence and associativity (neither are needed in languages whose expressions are written using prefix or postfix notation).
The plot below shows the tree derived from combining binary operator and the corresponding precedence information (the distance pairs for the two characteristics, for each language, were added together, with precedence given a weight of 20%; see code for details).

No bootstrap percentages appear because I could not come up with a simple technique for handling a combination of traits.
Are binary operators more representative of a language than its keywords? Would a combined keyword/binary operator tree would be more representative, or would more traits need to be included?
Does reducing language comparison to a single number produce something useful?
Languages contain a complex collection of interrelated components, and it might be more useful to compare their similarity by discrete components, e.g., expressions, literals, types (and implicit conversions).
What is the purpose of comparing languages?
If it is for promotional purposes, then a measurement based approach is probably out of place.
If the comparison has a source code orientation, weighting items by source code occurrence might produce a more applicable tree.
Sometimes one language is used as a reference, against which others are compared, e.g., C-like. How ‘C-like’ are other languages? Taking keywords as our reference-point, comparing languages based on just the keywords they have in common with C, the plot below is the resulting tree:

I had expected less branching, i.e., more languages having the same distance from C.
New languages can be supported by adding a language file containing the appropriate trait information. There is a Github repo, prog-lang-traits, send me a pull request to add your language file.
It’s also possible to add support for more language traits.