Derek Jones from The Shape of Code
A month or so ago, I found a graph showing a percentage of PCs having a given range of memory installed, between March 2000 and April 2020, on a TechTalk page of PC Matic; it had the form of a stacked density plot. This kind of installed memory data is rare, how could I get the underlying values (a previous post covers extracting data from a heatmap)?
The plot below is the image on PC Matic’s site:
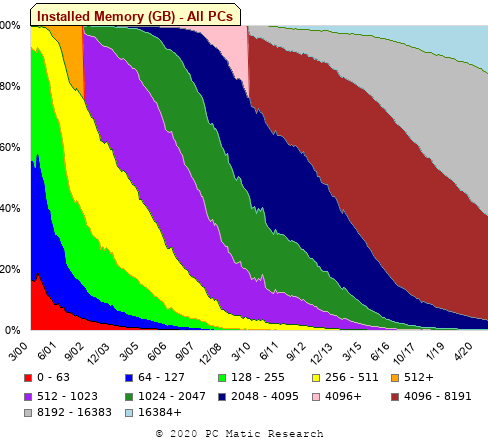
The change of colors creates a distinct boundary between different memory capacity ranges, and it ought to be possible to find the y-axis location of each color change, for a given x-axis location (with location measured in pixels).
The image was a png file, I loaded R’s png package, and a call to readPNG created the required 2-D array of pixel information.
library("png")
img=readPNG("../rc_mem_memrange_all.png")
Next, the horizontal and vertical pixel boundaries of the colored data needed to be found. The rectangle of data is surrounded by white pixels. The number of white pixels (actually all ones corresponding to the RGB values) along each horizontal and vertical line dramatically drops at the data image boundary. The following code counts the number of col points in each horizontal line (used to find the y-axis bounds):
horizontal_line=function(a_img, col)
{
lines_col=sapply(1:n_lines, function(X) sum((a_img[X, , 1]==col[1]) &
(a_img[X, , 2]==col[2]) &
(a_img[X, , 3]==col[3]))
)
return(lines_col)
}
white=c(1, 1, 1)
n_cols=dim(img)[2]
# Find where fraction of white points on a line changes dramatically
white_horiz=horizontal_line(img, white)
# handle when upper boundary is missing
ylim=c(0, which(abs(diff(white_horiz/n_cols)) > 0.5))
ylim=ylim[2:3]
Next, for each vertical column of pixels, at each x-axis pixel location, the sought after y value occurs at the change of color boundary in the corresponding vertical column. This boundary includes a 1-pixel wide separation color, which creates a run of 2 or 3 consecutive pixel color changes.
The color change is easily found using the duplicated function.
# Return y position of vertical color changes at x_pos
y_col_change=function(x_pos)
{
# Good enough technique to generate a unique value per RGB color
col_change=which(!duplicated(img[y_range, x_pos, 1]+
10*img[y_range, x_pos, 2]+
100*img[y_range, x_pos, 3]))
# Handle a 1-pixel separation line between colors.
# Diff is used to find these consecutive sequences.
y_change=c(1, col_change[which(diff(col_change) > 1)+1])
# Always return a vector containing max_vals elements.
return(c(y_change, rep(NA, max_vals-length(y_change))))
}
Next, we need to group together the sequence of points that delimit a particular boundary. The points along the same boundary are all associated with the same two colors, i.e., the ones below/above the boundary (plus a possible boundary color).
The plot below shows all the detected boundary points, in black, overwritten by colors denoting the points associated with the same below/above colors (code):
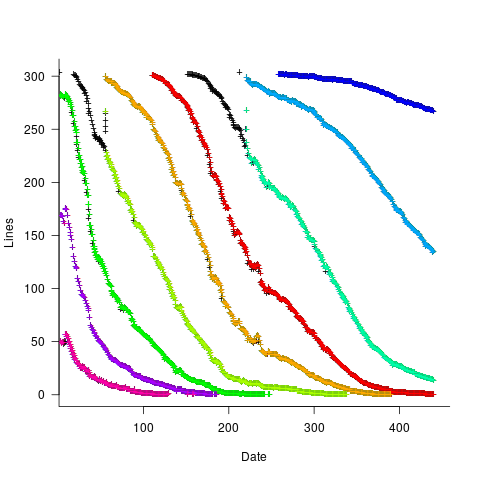
The visible black pluses show that the algorithm is not perfect. The few points here and there can be ignored, but the two blocks at the top of the original image have thrown a spanner in the works for some range of points (this could be fixed manually, or perhaps it is possible to tweak the color extraction formula to work around them).
How well does this approach work with other stacked density plots? No idea, but I am on the lookout for other interesting examples.
 The data does not include a description of the columns, but most of the names appear self-explanatory (I have no idea what key might be). Each of the 3,761 rows includes a story-point estimate, team-id, and a tag name for the work item.
The data does not include a description of the columns, but most of the names appear self-explanatory (I have no idea what key might be). Each of the 3,761 rows includes a story-point estimate, team-id, and a tag name for the work item. to state In Development at time
to state In Development at time  , and was still in state In Development at time
, and was still in state In Development at time  (when the snapshot was taken); the
(when the snapshot was taken); the  is a small interval used to separate the states.
is a small interval used to separate the states. , where
, where  is the mean length.
is the mean length.
 , where
, where  is the mean length.
is the mean length.