Derek Jones from The Shape of Code
The mission statement of the Software Heritage is “… to collect, preserve, and share all software that is publicly available in source code form.”
What are the uses of the preserved source code that is collected? Lots of people visit preserved buildings, but very few people are interested in looking at source code.
One use-case is tracking the evolution of changes in developer usage of various programming language constructs. It is possible to use Github to track the adoption of language features introduced after 2008, when the company was founded, e.g., new language constructs in Java. Over longer time-scales, the Software Heritage, which has source code going back to the 1960s, is the only option.
One question that keeps cropping up when discussing the C Standard, is whether K&R C continues to be used. Technically, K&R C is the language defined by the book that introduced C to the world. Over time, differences between K&R C and the C Standard have fallen away, as compilers cease supporting particular K&R ways of doing things (as an option or otherwise).
These days, saying that code uses K&R C is taken to mean that it contains functions defined using the K&R style (see sentence 1818), e.g.,
writing:
int f(a, b)
int a;
float b;
{
/* declarations and statements */
}
rather than:
int f(int a, float b)
{
/* declarations and statements */
}
As well as the syntactic differences, there are semantic differences between the two styles of function definition, but these are not relevant here.
How much longer should the C Standard continue to support the K&R style of function definition?
The WG14 committee prides itself on not breaking existing code, or at least not lots of it. How much code is out there, being actively maintained, and containing K&R function definitions?
Members of the committee agree that they rarely encounter this K&R usage, and it would be useful to have some idea of the decline in use over time (with the intent of removing support in some future revision of the standard).
One way to estimate the evolution in the use/non-use of K&R style function definitions is to analyse the C source created in each year since the late 1970s.
The question is then: How representative is the Software Heritage C source, compared to all the C source currently being actively maintained?
The Software Heritage preserves publicly available source, plus the non-public, proprietary source forming the totality of the C currently being maintained. Does the public and non-public C source have similar characteristics, or are there application domains which are poorly represented in the publicly available source?
Embedded systems is a very large and broad application domain that is poorly represented in the publicly available C source. Embedded source tends to be heavily tied to the hardware on which it runs, and vendors tend to be paranoid about releasing internal details about their products.
The various embedded systems domains (e.g., 8, 16, 32, 64-bit processor) tend to be a world unto themselves, and I would not be surprised to find out that there are enclaves of K&R usage (perhaps because there is no pressure to change, or because the available tools are ancient).
At the moment, the Software Heritage don’t offer code search functionality. But then, the next opportunity for major changes to the C Standard is probably 5-years away (the deadline for new proposals on the current revision has passed); plenty of time to get to a position where usage data can be obtained 
 , where:
, where:  is the time taken to do the task,
is the time taken to do the task, is some measure of practice (such as the number of times the subject has performed the task), and
is some measure of practice (such as the number of times the subject has performed the task), and  ,
,  , and
, and  are constants fitted to the data.
are constants fitted to the data. . The power law appeared to be the result of aggregating the exponential response performance of multiple subjects; oops.
. The power law appeared to be the result of aggregating the exponential response performance of multiple subjects; oops. (
(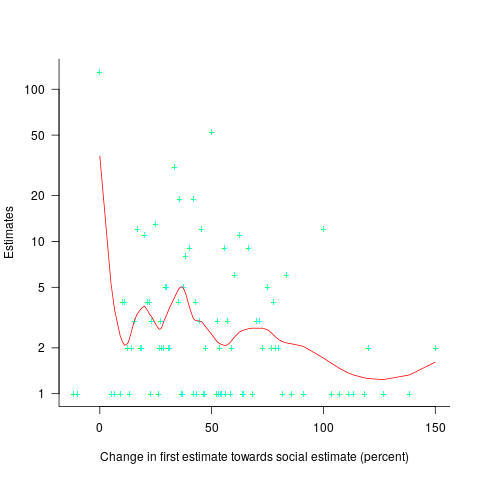
 explains nearly all the variance present in the data.
explains nearly all the variance present in the data.
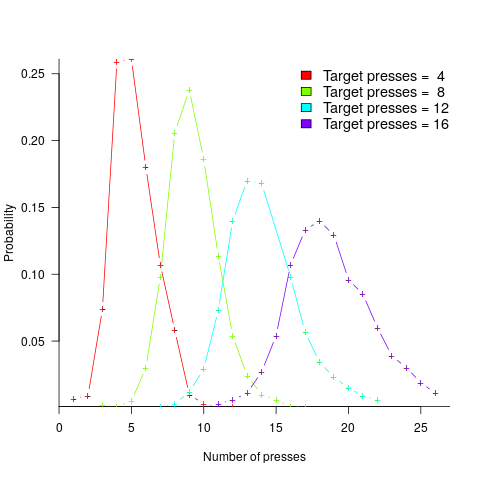
 , and red line a fitted regression model having the form
, and red line a fitted regression model having the form  (which explains just over 70% of the variance;
(which explains just over 70% of the variance; 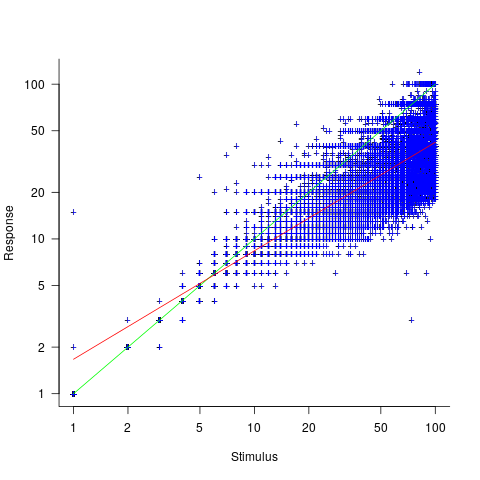
 , with
, with  varying between 0.65 and 1.57; more than a factor of two difference between subjects (this model explains just under 90% of the variance). This is a smaller range than the software estimation data, but with only six subjects there was less chance of a wider variation (
varying between 0.65 and 1.57; more than a factor of two difference between subjects (this model explains just under 90% of the variance). This is a smaller range than the software estimation data, but with only six subjects there was less chance of a wider variation (