Derek Jones from The Shape of Code
The idea of proving programs correct, like mathematical proofs, is appealing, but is based on an incorrect assumption often made by non-mathematicians, e.g., mathematical proofs are fault free. In practice, mathematicians make mistakes and create proofs that contain serious errors; those of us who are taught mathematical techniques, but are not mathematicians, only get to see the good stuff that has been checked over many years.
An appreciation that published proofs contain mistakes is starting to grow, but Magnificent mistakes in mathematics is an odd choice for a book title on the topic. Quotes from De Millo’s article on “Social Processes and Proofs of Theorems and Programs” now appear regularly; On proof and progress in mathematics is worth a read.
Are there patterns to the faults that appear in claimed mathematical proofs?
- The difficulty of the problem is one obvious issue, as shown by the faulty proofs of the N vs. NP problem,
- the size of the proof, in number of pages, is a common problem, with Mochizuki’s ‘proof’ of the ABC conjecture being a recent example and the Hales-Ferguson proof of the Kepler conjecture has a whole book dedicated to trying to figure out if the proof is correct,
- number of people involved: some of the 100+ mathematicians responsible for proving components of the classification of finite simple groups died before the proof was claimed to be complete; the proofs of the various components created the largest known claimed proof, at tens of thousands of pages.
A surprisingly common approach, used by mathematicians to avoid faults in their proofs, is to state theorems without giving a formal proof (giving an informal one is given instead). There are plenty of mathematicians who don’t think proofs are a big part of mathematics (various papers from the linked-to book are available as pdfs).
Next time you encounter an advocate of proving programs correct using mathematics, ask them what they think about the uncertainty about claimed mathematical proofs and all the mistakes that have been found in published proofs.
 .
.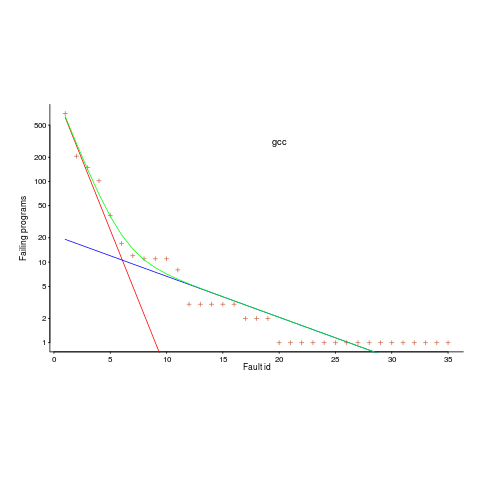
 is that one exponential is driven by the presence of faults in the code and the other exponential is driven by the way in which Csmith meanders over the possible C source.
is that one exponential is driven by the presence of faults in the code and the other exponential is driven by the way in which Csmith meanders over the possible C source.