Derek Jones from The Shape of Code
At the end of March a paper modelling the impact of various scenarios on the spread of COVID-19 infections, by the MRC Centre for Global Infectious Disease Analysis at Imperial College, appears to have influenced the policy of the powers that be. This group recently started publishing their modelling code on Github (good for them).
Most of my professional life has been spent analyzing other peoples’ code, for one reason or another (mostly Fortran, then Pascal, and then C). I had heard that the Imperial software was written in C, but the released code is written in R (as of six hours ago there is the start of a Python version). Ok, I can work with R, but my comments will be general, since I don’t have lots of in depth experience reading R code.
The code comes from a research context, and is evolving, i.e., some amount of messiness is to be expected.
There is not a lot of code to talk about (248 lines setting things up, 111 lines for a Stan model, 371 lines of plotting code, and 85 lines of utility code). The analysis is performed by creating a model using the Stan statistical inference language (in which the high level structure of the problem is specified, compiled to a lower level form and then run; the Stan language is very similar to R). These days lots of problems are coded using a relatively small number of lines that call fancy libraries to do the heavy lifting. It is becoming rare to have to write tens of thousands of lines of code to solve a problem.
I have two points to make about the code, all designed to reduce the likelihood of mistakes being made by the person working on the source. These points mainly apply to the Stan code, because that is where the important stuff happens, but are equally applicable to all code.
- Numeric literals are embedded in the code, values include:
2.4,1.0,0.5,0.03,1e-5, and1e-9. These values obviously mean something to the person who wrote the code, and they can probably be interpreted by experts in the spread of virus infections. But why are they scattered about the code, rather than appearing together (as a sequence of assignments to variables with meaningful names)? Having all the constants in one place makes it easier to spot when a mistake has been made, e.g., one value has been changed without a corresponding change in another value; it also makes it easier for people new to the code to figure out what is going on, - when commenting out code, make it very obvious, e.g., have
/**********************on its own line, and*****************************/on its own line. Using just/*and*/makes it easy to miss that code has been commented out.
Why have they started a Python implementation? Perhaps somebody on the team is more comfortable working with Python (when deadlines loom, it is always best to go with what you know).
Having both an R and Python version is good, in that coding mistakes are likely to show up as inconsistencies in the results produced. It’s always good to have the output of two independently written programs to compare (apart from the fact it may cost twice as much).
The README mentions performance issues. I imagine that most of the execution time is spent in the Stan code, so R vs. Python is not a performance issue.
Any reader with expertise tuning Stan models for performance might like to check out the code. I’m sure the Imperial folk would be happy to hear about worthwhile speed-ups.


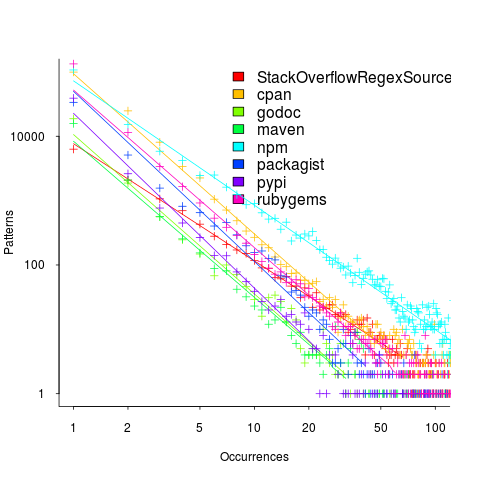
 , where:
, where:  is driven by the total amount of source processed and the frequency of occurrence of regexs in source, and
is driven by the total amount of source processed and the frequency of occurrence of regexs in source, and  is the rate at which duplicates occur.
is the rate at which duplicates occur.