fixing c++ with epochs
fixing c++ with epochs
a.k. from thus spake a.k.
Allan Kelly from Allan Kelly Associates

Those of us who don’t code any more, and perhaps many of those who do, need Electronic Monks to help us with software development.
There is an old Douglas Adam’s book (Dirk Gently’s Holistic Detective Agency) which features an Electric Monk. The job of an electric monk is to believe things for you. In Adam’s story people have too many things to believe so they offload all that believing to an electric monk. In my mind I’ve always considered part of the monk’s work to include worrying. I can’t remember if Adam’s says this explicitly or just implies it. (And as I no longer have a copy of the book I can’t check.)
I’m currently very engaged with one client as an Agile Coach (although I sometimes wonder if “Shadow Manager†might be a better term, more of that another day). I regularly find myself staring at the board thinking about the work it shows and worrying about whether it will be done. Sometimes my mind plays “what if games†– “If that card is finished soon, then the other one could move down and…â€
The same worry plays out when looking at the backlog showing work not on the board. Or when I’m talking to the Product Owner. Or indeed when I find myself talking to middle managers and others in the company who have an interest in the work the team is doing.
Basically, there is very little any of us can do to move the work through.
Sure I can call a meeting and talk about optimising our workflow. But I’ve done that a few times already.
I could call a meeting and emphasis how important the work is to the company. I’ve seen this done many times. Some non-coders – call them “the business†– seem to think “If only the coders appreciated how important this work was then they would do it faster.†I hated this when I was a coder and I hate it when I hear others saying things like “Do they know how important this is?†Business folk sometimes seem to believe coders sit around drinking tea and coffee for most of the day.
By the way, I almost wrote “and Testers†in that last paragraph but then realised testers CAN make work go faster: they can just drop their standards, turn a blind eye to issues, accept things they wouldn’t have accepted last week. Piling pressure on Testers is a more effective route to getting work done than pressuring coders. But in both cases it is probably just piling up more work.
Pressuring people to do work faster usually creates problems which come a back and bite you pretty damn quick. As I’ve said before: There is no such thing as “Quick and Dirty†… “Quick and Dirty†actually means “Slow and Dirtyâ€
I could go to the coders and ask “Are you done yet?†– or as 5-year olds say in the back of a car on a long journey (or just any journey) “Are we there yet?†In both cases it doesn’t change the time it takes to get to the end, the answer doesn’t usually say much but asking the question will annoy parents and coders alike.
But if I do anything – like calling a meeting or asking “are we there yet?†– which involves distracting coders from working then I am slowing work down. It is self-defeating.
Yes there are things I can do to make work go more smoothly but once a piece of work is in flight there is little I can do. Most of the change I can make are to do with the way work happens. Or to put it another way: I can influence the climate work happens in but I can’t control the individual weather events which are the work items.
All I can do is worry. Thus my desire to offload that worrying to an electronic monk. Maybe more people in and around software developerment need to recognise they are in the same position.
Like this post? – Like to receive these posts by e-mail?
Check out my latest books – Continuous Digital and Project Myopia – and the Project Myopia audio edition
The post Are we there yet? appeared first on Allan Kelly Associates.
Derek Jones from The Shape of Code
The average new graduate is likely to do more programming during the first month of a software engineering job, than they did during a year as an undergraduate. Programming courses for undergraduates is really about filtering out those who cannot code.
Long, long ago, when I had some connection to undergraduate hiring, around 70-80% of those interviewed for a programming job could not write a simple 10-20 line program; I’m told that this is still true today. Fluency in any language (computer or human) takes practice, and the typical undergraduate gets very little practice (there is no reason why they should, there are lots of activities on offer to students and programming fluency is not needed to get a degree).
There is lots of academic discussion around which language students should learn first, and what languages they should be exposed to. I have always been baffled by the idea that there was much to be gained by spending time teaching students multiple languages, when most of them barely grasp the primary course language. When I was at school the idea behind the trendy new maths curriculum was to teach concepts, rather than rote learning (such as algebra; yes, rote learning of the rules of algebra); the concept of number-base was considered to be a worthwhile concept and us kids were taught this concept by having the class convert values back and forth, such as base-10 numbers to base-5 (base-2 was rarely used in examples). Those of us who were good at maths instantly figured it out, while everybody else was completely confused (including some teachers).
My view is that there is no major teaching/learning impact on the choice of first language; it is all about academic fashion and marketing to students. Those who have the ability to program will just pick it up, and everybody else will flounder and do their best to stay away from it.
Richard Reid was interested in knowing which languages were being used to teach introductory programming to computer science and information systems majors. Starting in 1992, he contacted universities roughly twice a year, asking about the language(s) used to teach introductory programming. The Reid list (as it became known), was regularly updated until Reid retired in 1999 (the average number of universities included in the list was over 400); one of Reid’s ex-students, Frances VanScoy, took over until 2006.
The plot below is from 1992 to 2002, and shows languages in the top 3% in any year (code+data):
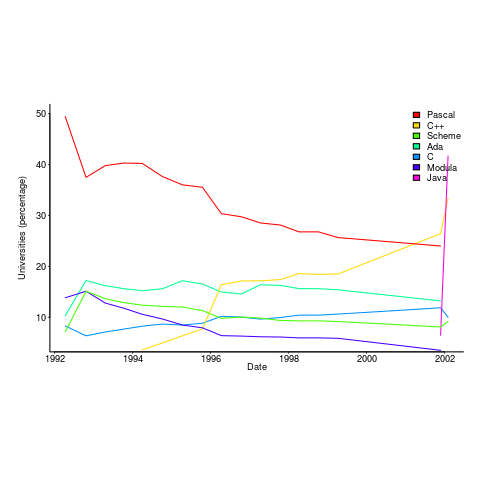
Looking at the list again reminded me how widespread Pascal was as a teaching language. Modula-2 was the language that Niklaus Wirth designed as the successor of Pascal, and Ada was intended to be the grown up Pascal.
While there is plenty of discussion about which language to teach first, doing this teaching is a low status activity (there is more fun to be had with the material taught to the final year students). One consequence is lack of any real incentive for spending time changing the course (e.g., using a new language). The Open University continued teaching Pascal for years, because material had been printed and had to be used up.
C++ took a while to take-off because of its association with C (which was very out of fashion in academia), and Java was still too new to risk exposing to impressionable first-years.
A count of the total number of languages listed, between 1992 and 2002, contains a few that might not be familiar to readers.
Ada Ada/Pascal Beta Blue C
1087 1 10 3 667
C/Java C/Scheme C++ C++/Pascal Eiffel
1 1 910 1 29
Fortran Haskell HyperTalk ISETL ISETL/C
133 12 2 30 1
Java Java/Haskell Miranda ML ML/Java
107 1 48 16 1
Modula-2 Modula-3 Oberon Oberon-2 ObjPascal
727 24 26 7 22
Orwell Pascal Pascal/C Prolog Scheme
12 2269 1 12 752
Scheme/ML Scheme/Turing Simula Smalltalk SML
1 1 14 33 88
Turing Visual-Basic
71 3
I had never heard of Orwell, a vanity language foisted on Oxford Mathematics and Computation students. It used to be common for someone in computing departments to foist their vanity language on students; it enabled them to claim the language was being used and stoked their ego. Is there some law that enables students to sue for damages?
The 1990s was still in the shadow of the 1980s fashion for functional programming (which came back into fashion a few years ago). Miranda was an attempt to commercialize a functional language compiler, with Haskell being an open source reaction.
I was surprised that Turing was so widely taught. More to do with the stature of where it came from (university of Toronto), than anything else.
Fortran was my first language, and is still widely used where high performance floating-point is required.
ISETL is a very interesting language from the 1960s that never really attracted much attention outside of New York. I suspect that Blue is BlueJ, a Java IDE targeting novices.
Allan Kelly from Allan Kelly Associates

I was on a panel last year when someone asked that old chestnut:
“Surely before you start coding anything you need to design an architecture?â€
As regular readers might guess I took a very simple stand:
“No, you need to get something that works, you need to show you can address the problem in a way that delivers business benefit. You can retrofit architecture when you have shown that your thing is useful and valuable. Sure spend some time thinking about design and architecture but this should be measured in hours not days. As the system grows return to these discussions but keep them to hours not days. Embrace emergent design and refactoring.â€
Another panellist disagreed:
“And…â€
In 2018 you can tell someone is about to disagree with you because they don’t start “No†or “But†they start “Andâ€
“Companies have databases, and data centres, and standards, and you need to spend some time thinking about them. You need to integrate to existing systems. Changing database schema’s, let alone database application servers is big work and you want to avoid it if you can.â€
OK, I can’t remember his exact words but that is the tone I recall. I was told, I was wrong.
Despite all those very real concerns I stand by my position. OK, maybe I need to elaborate a bit so here goes…
The thing is, I have nothing against architecture. When you build a software system you will – before very long – have an architecture. It may not be a very good one but you will have one.
I encourage all developers to study software design and architecture. Coders make hundreds, even thousands, of decisions everyday when they are coding and there is an architectural angle to every decision. Coders need to be versed in good design practices so they make good decisions.
Nor do I have anything against guiding the architecture in such a way that it becomes better with time – indeed I think that is a necessity. Neither do I disagree with architectural conventions in a system or documentation, again they become more valuable with time.
What I’m not in favour of is: believing that you can set it from the start. I believe the more you try to predetermine the more time you will waste.
Architecture is nine-tenths what you have, and one-tenth what you think you have, or should have. Architecture exists in the minds and shared models of those who maintain the system as much as it does in the code.
There are some occasion when there is a completely blank sheet of paper to start with. New start-ups spring obviously, but even inside a large corporation there are occasions when it happens; say when the company wants to experiment with new technologies and approaches, or hedge options. There are two priorities here:
So: pick the solutions that seem right to you now – thats “you†plural, you and the team you are working with.
Maybe spend a little time considering your options (Oracle? MySql? CouchBase? Mongo?) but don’t spend too long, hours not days. Accept that you will learn when you start using your chosen option and accept that you may change it, or that you may make a bad decision and be cursing you decision for ever more.
The thing is: all that time spent designing the architecture, researching options and making decisions is wasted if you do not deliver business benefit. If nobody uses it then having the perfect product, perfect architecture, is pointless.
Anyway, even if you spend months and agree the perfect architecture it will not survive. Once you start work you will find assumptions invalidated, you will find things don’t work as you expected, and you will find that the cheap code monkeys you hired to implement you wonderful design do things you didn’t expect.
Now consider the case where you start a new initiative in an existing environment. There are existing databases and systems to work with. Again you don’t need to spend a lot of time looking at options because you don’t have them. Instead you have constraints.
If the company standard is Oracle for databases you are going to use Oracle.
If you need to integrate with SalesForce then you need to integrate with SalesForce.
You might believe that CouchBase is a better solution than Oracle from the word go. In which case you can either:
Or
What I would not do is: embark on a lengthy examination of all the possible options with the aim of deciding which is best. This takes time and means you will deliver later, which means cost-of-delay will reduce the value you deliver. Sure the great design might generate slightly more business benefit, or get sightly more performance from your development team but you are also delaying.
If you start with a good-enough solution you will learn. That learning may change your opinion, or it might confirm your initial opinion.
Remember: You are not building the ideal system. You are building the best system you can within constraints. The best system you can with the time and money available. In an existing environment many of those constraints are usually given before you start.
Unfortunately, us development folk tend to limit options thinking and exploring to the initial stages of a development effort – usually before any code is written. Once work is underway they don’t consider options often enough, we tend to jump at the first solution we think of.
Like this post? – Like to receive these posts by e-mail?
Check out my latest books – Continuous Digital and Project Myopia – and the Project Myopia audio edition
The post In the beginning there is architecture, well maybe appeared first on Allan Kelly Associates.
Derek Jones from The Shape of Code
The corruption that pervades the academic publishing system has become more public.
There is now a website that makes use of an ingenious technique for helping people increase their paper count (as might be expected, the competitive China thought of it first). Want to be listed as the first author of a paper? Fees start at $500. The beauty of the scheme is that the papers have already been accepted by a journal for publication, so the buyer knows exactly what they are getting. Paying to be included as an author before the paper is accepted incurs the risk that the paper might not be accepted.
Measurement of academic performance is based on number of papers published, weighted by the impact factor of the journal in which they are published. Individuals seeking promotion and research funding need an appropriately high publication score; the ranking of university departments is based on the publications of its members. The phrase publish or perish aptly describes the process. As expected, with individual careers and departmental funding on the line, the system has become corrupt in all kinds of ways.
There are organizations who will publish your paper for a fee, 100% guaranteed, and you can even attend a scam conference (that’s not how the organizers describe them). Problem is, word gets around and the weighting given to publishing in such journals is very low (or it should be, not all of them get caught).
The horror being expressed at this practice is driven by the fact that money is changing hands. Adding a colleague as an author (on the basis that they will return the favor later) is accepted practice; tacking your supervisors name on to the end of the list of authors is standard practice, irrespective of any contribution that might have made (how else would a professor accumulate 100+ published papers).
I regularly receive emails from academics telling me they would like to work on this or that with me. If they look like proper researchers, I am respectful; if they look like an academic paper mill, my reply points out (subtly or otherwise) that their work is not of high enough standard to be relevant to industry. Perhaps I should send them a quote for having their name appear on a paper written by me (I don’t publish in academic journals, so such a paper is unlikely to have much value in the system they operate within); it sounds worth doing just for the shocked response.
I read lots of papers, and usually ignore the list of authors. If it looks like there is some interesting data associated with the work, I email the first author, and will only include the other authors in the email if I am looking to do a bit of marketing for my book or the paper is many years old (so the first author is less likely to have the data).
I continue to be amazed at the number of people who continue to strive to do proper research in this academic environment.
I wonder how much I might get by auctioning off the coauthoship of my software engineering book?
Products, the Universe and Everything from Products, the Universe and Everything
This is a recommended maintenance update for Visual Lint 7.0. The following changes are included:
Added a +rw(noexcept) directive to the Visual Studio 2015 and 2017 PC-lint 9.0 compiler indirect files co-msc140.lnt and co-rb-vs2017.lnt respectively. This allows code which uses the noexcept keyword to be analysed more cleanly.
As PC-lint 9.0 does not officially support modern C++ code other analysis errors may still occur when you analyse modern C++ code with PC-lint 9.0. As such we recommend that you update to PC-lint Plus to analyse code for modern C++ compilers such as GCC 4.x/5.x or Visual Studio 2013/15/17/19. Please contact us for details.
Fixed a bug in the installer which could prevent the Visual Studio plug-in from being installed to Visual Studio 2019.
Fixed a bug in the VisualLintGui Products Display "Add Existing File" context menu command.
Fixed a bug in the update check process which could result in incorrect text being displayed for a major update (e.g. to Visual Lint 7.x) [also in Visual Lint 6.5.8.309].
Products, the Universe and Everything from Products, the Universe and Everything
This is a recommended maintenance update for Visual Lint 7.0. The following changes are included:
student from thus spake a.k.
Fran from BuontempoConsulting
I asked twitter who is using decision trees and what for. Most were using them, unsurprisingly, to make decisions. It wasn't always clear how the trees themselves were built.