Derek Jones from The Shape of Code
Who are the major players in evidence-based software engineering?
How might ‘majorness’ of players be calculated? For me, the amount of interesting software engineering data they have made publicly available is the crucial factor. Any data published in a book, paper or report is enough to be considered interesting. How interesting is data published on a web page? This is a tough question, let’s dodge the question to start with, and consider the decades before the start of 2000.
In the academic world performance is based on number of papers published, the impact factor of where they were published and number of citations of those papers. This skews the results in favor of those with lots of students (who tack their advisor’s name on the end of papers published) and those who are good at marketing.
Historians of computing have primarily focused on the evolution of hardware and are slowly moving to discuss software (perhaps because microcomputers have wiped out nearly every hardware vendor). So we will have to wait perhaps a decade or two for tentative/definitive historian answer.
The 1950s
Computers and Automation is a criminally underused resource (a couple of PhDs worth of primary data here). A lot of the data is hardware related, but software gets a lot more than a passing mention.
The US military published lots of hardware data, but software does not get mentioned much.
The 1960s
Computers and Automation are still publishing.
The US military still publishing data; again mostly hardware related.
Datamation, a weekly news magazine, published a lot of substantial material on the software and hardware ecosystems as they evolved.
Kenneth Knight’s analysis of computer performance is an example of the kind of data analysis that many people undertook for hardware, which was rarely done for software.
The 1970s
The US military are still leading the way; we are in the time of Rome. Air Force officers studying for a Master’s degree publish more software engineering data than all academics combined over this and the next two decades.
“Data processing technology and economics†by Montgomery Phister is 720 A4 pages packed with graphs and tables of numbers. Despite citing earlier sources, this has become the primary source for a lot of subsequent researchers; this is understandable in a pre-internet age. Now we have Bitsavers and the Internet Archive, and the cited primary source can be downloaded.
NASA is surprisingly low volume.
The 1980s
Rome falls (i.e., the work gets outsourced to a university) and the false prophets (i.e., academics doing non-evidence based work) multiply and prosper. There are hushed references to trouble makers performing unclean acts experiments in the wilderness.
A few people working in the wilderness, meaning that the quantity of data being produced drops by at least an order of magnitude.
The 1990s
Enough time has passed for people to be able to refer to the wisdom of the ancients.
There are still people in the wilderness howling at the moon, and performing unclean acts experiments.
The 2000s
Repositories of Open source and bug reports grow and prosper. Evidence-based software engineering research starts to become mainstream.
There are now groups of people doing software engineering research.
What about individuals as major players? A vaguely scientific way of rating individual impact, on evidence-based software engineering, is to count the number of papers they have published, that are cited by a book claiming to discuss all the important/interesting publicly available software engineering data (code+data).
The 1,521 papers cited, by such a book, had 3,716 authors, of which 3,095 were different. The authors who appeared most often are listed below (count on the right, and yes, at number 2 is a theoretician; I have cited myself nine times, but two of those are to web sites hosting data).
Magne Jorgensen 17
Anne Chao 11
Dag I. K. Sjoberg 10
Massimiliano Di Penta 10
Ahmed E. Hassan 8
Christian Bird 8
Stanislas Dehaene 8
Giuliano Antoniol 7
Thomas Zimmermann 7
Alexander Serebrenik 6
Dror G. Feitelson 6
Gregorio Robles 6
Krzysztof Czarnecki 6
Lutz Prechelt 6
Victor R. Basili 6
The number of authors/papers follows the usual pattern of many people writing one paper.
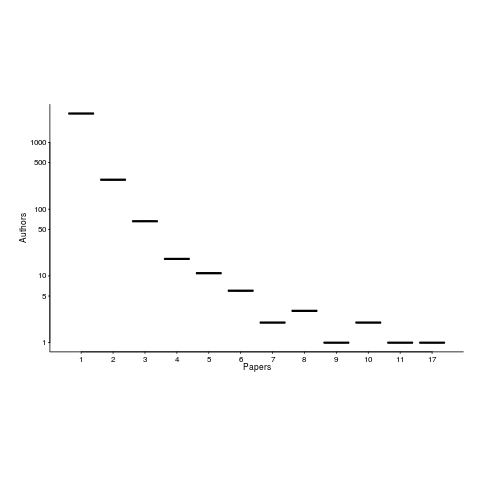
Who might I have missed? The business school researchers don’t get a mention because their data is often covered by a confidentiality agreement. The machine learning crowd are just embarrassing.
Suggestions for major players welcome.

