When reading code, starting at the first line of a function/method, the probability of the next statement read being a for-loop is around 1.5% (at least in C, I don’t have decent data on other languages). Let’s say you have been reading the code a line at a time, and you are now reading lines nested within various if/while/for statements, you are at nesting depth . What is the probability of the statement on the next line being a for-loop?
Does the probability of encountering a for-loop remain unchanged with nesting depth (i.e., developer habits are not affected by nesting depth), or does it decrease (aren’t developers supposed to using functions/methods rather than nesting; I have never heard anybody suggest that it increases)?
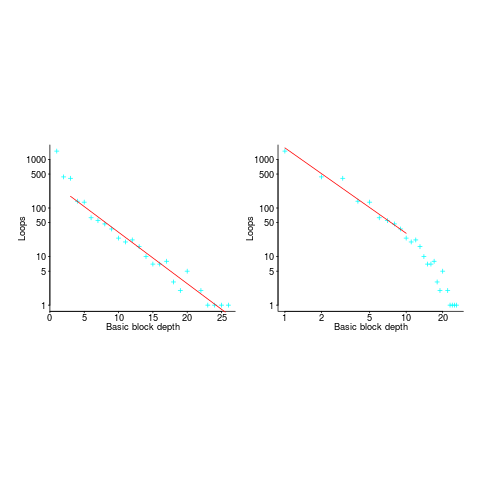
If you think the for-loop use probability is not affected by nesting depth, you are going to argue for the plot on the left (below, showing number of loops appearing in C source at various nesting depths), with the regression model fitting really well after 3-levels of nesting. If you think the probability decreases with nesting depth, you are likely to argue for the plot on the right, with the model fitting really well down to around 10-levels of nesting (code+data).
Both plots use the same data, but different scales are used for the x-axis.
If probability of use is independent of nesting depth, an exponential equation should fit the data (i.e., the left plot), decreasing probability is supported by a power-law (i.e, the right plot; plus other forms of equation, but let’s keep things simple).
The two cases are very wrong over different ranges of the data. What is your explanation for reality failing to follow your beliefs in for-loop occurrence probability?
Is the mismatch between belief and reality caused by the small size of the data set (a few million lines were measured, which was once considered to be a lot), or perhaps your beliefs are based on other languages which will behave as claimed (appropriate measurements on other languages most welcome).
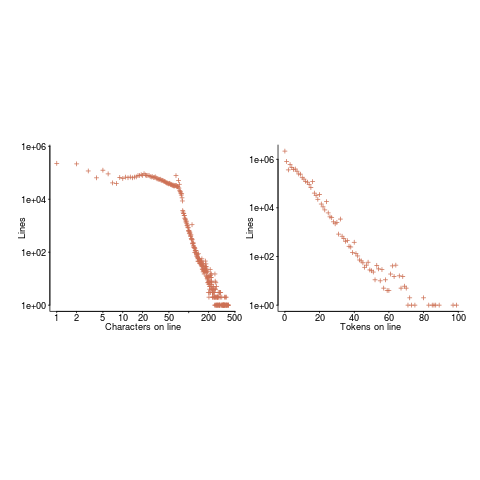
The nesting depth dependent use probability plot shows a sudden change in the rate of decrease in for-loop probability; perhaps this is caused by the maximum number of characters that can appear on a typical editor line (within a window). The left plot (below) shows the number of lines (of C source) containing a given number of characters; the right plot counts tokens per line and the length effect is much less pronounced (perhaps developers use shorter identifiers in nested code). Note: different scales used for the x-axis (code+data).
I don’t have any believable ideas for why the exponential fit only works if the first few nesting depths are ignored. What could be so special about early nesting depths?
What about fitting the data with other equations?
A bi-exponential springs to mind, with one exponential driven by application requirements and the other by algorithm selection; but reality is not on-board with this idea.
Ideas, suggestions, and data for other languages, most welcome.
In the first part, I described how I set up the basic OpenBSD WireGuard VPN server. I also hinted that I wanted to set up my own validating, filtering DNS server. With a little bit of spare time during the holidays I decided now was a good time as any. Making sure the VPN server […]
In the first part, I described how I set up the basic OpenBSD WireGuard VPN server. I also hinted that I wanted to set up my own validating, filtering DNS server. With a little bit of spare time during the holidays I decided now was a good time as any.
Making sure the VPN server uses the local Unbound DNS resolver first Before I set up Unbound itself, I need to make sure that the VPN server’s resolv.
“Planning has rapidly diminishing returns: plan less, do more, learn more, redesign governance to kill early and often.”
Happy new year! – There is always a special responsibility that comes with the first blog post of a new year. Fortunately Tom Cagley of SpamCast fame asked me a fantasy question:
If there is one piece of advice you would give to CxO executives what would it be?
There is plenty of advice I’d like to give them, but one piece of advice?
One piece of advice which is generic and cuts across industry upon industry. One piece of advice for all those companies I know nothing about.
Tough. When I eventually came up with my answer I knew I’d have to explain it.
I had to think long and hard. I knew immediately that it would be something on the continuous digital theme. (One piece of advice for budding authors: don’t write long books, I knew this already then I mistakenly wrote Continuous Digital, that should have been four books.)
Eventually I came up with this:
“Planning has rapidly diminishing returns: plan less, do more, learn more, redesign governance to kill early and often.”
I believe this is universally true. Plan anything for long enough and you will eventually plan your way out of doing anything. When I run my Extended XP Game I regularly see teams plan their way out of good approaches to work.
Some planning adds a lot of value. But the rate of learning slows and continues to slow. At some point you aren’t learning more at all, and sometime after that your learning is counter productive. As economists say: there are diminishing returns on the investment.
A little planning adds a lot of value. But each extra minute of planning adds less value than the previous minute. Plan a little, do a little.
In our modern technology driven world two factors make this especially true.
One: learning by doing is faster with modern technology
Technology has advanced: Moore’s Law means I have over 100 times as much power in my MacBook Air as I did in the 6502 BBC Micro I learned to program on in the 1980s. That in turn had more power than the IBM Mainframes of the late 1960s.
That means our tools are more powerful: the Python I programme in today isn’t the most powerful language but it is a damn site more powerful than 6502 assembler and BBC Basic. Add open source libraries and that Python is immensely more powerful than writing in 1960s COBOL.
As a result things that tool months or years to create take hours and days. A week of planning for a OS/360 COBOL program that will take 6 months to write makes sense. A week of planning for a Python program I’ll have running in the cloud by the end of next week doesn’t.
And when I say planning I mean all aspect of planning: research, requirements, schedules, architecture designs and the rest.
Sure a bit of planning makes complete sense. I would be stupid not to make a coffee and think about what I was about to do. But planning is all about learning, is about experiencing the future a little bit. The power of our tools today means that future is a lot closer, and the most rapid way to learn about it is to create it.
Once I reach that future it makes sense to stop, review and plan again. The quickest way to learn is to alternate thinking (that is “planningâ€) and action (learning by doing.) Do something, see what works, then take time to reflect and learn.
Doing is learning too. The question at any given point is: what is the fastest way to learn? In the beginning that is planning, very soon doing becomes faster.
Now remember: planning time is time, planning delays launch. Keep planning, analysing, talking to potential customers, drawing imaginary project plans or perfecting your architecture (before you start building) all delays the time you will get a product into the market.
That delay is bad because it increases risk: until your product is in the market you are at risk of creating a product nobody wants, or at least nobody will pay for.
That delay means your product will earn less money – thats cost of delay. Potential customers may have found other solutions, competitors may have got there first, or technology advances may render your product obsolete.
Lets be straight: I’m not saying No Planning. A little planning can be really really useful and valuable. So please plan!
What I am saying is: plan a little, do a little. Repeat.
Then stop, reflect, evaluate, and plan a little more before you do a bit. Alternate planning and doing. I’m not original in saying that, the Shewhart cycle (i.e. the Deming cycle or PDCA), says the same and so do half a dozen other approaches.
The problem is: many executives have been taught to plan plan plan. Nobody ever gets in trouble for planning too much and most failures can be traced back to a failure to plan more if you try hard enough. Ultimately, if you plan enough you will never have any failures because you will never do anything.
Which brings me to the last part of that executive advice: “redesign governance to kill early and often.”
Organizational governance is overwhelmingly based on the assumption that we know what we are doing. Only things that are very well understood will be allowed to start. That incentivises people to plan plan plan. And when something does get started there is a bias against closing it down (inertia and commitment escalation).
That needs to change. Since we can’t know in advance we need to be able to react once work is in flight.
Organizations need to be prepared to start work where the outcome is vague. Governance then needs to kill initiatives which aren’t showing promise. Put it another way: the early stage gates need less rigorous and the later ones more rigourous. If governance isn’t killing initiatives often then either governance isn’t working or you aren’t taking enough risk.
Like this post? – Like to receive these posts by e-mail?
Looking back, the 1970s appear to be a golden age of software engineering research, with the following decades being the dark ages (i.e., vanity research promoted by ego and bluster), from which we are slowly emerging (a rough timeline).
Lots of evidence-based software engineering research was done in the 1970s, relative to the number of papers published, and I have previously written about the quantity of research done at Rome and the rise of ego and bluster after its fall (Air Force officers studying for a Master’s degree publish as much software engineering data as software engineering academics combined during the 1970s and the next two decades).
What is the evidence for a software engineering research dark ages, starting in the 1980s?
One indicator is the extent to which ancient books are still venerated, and the wisdom of the ancients is still regularly cited.
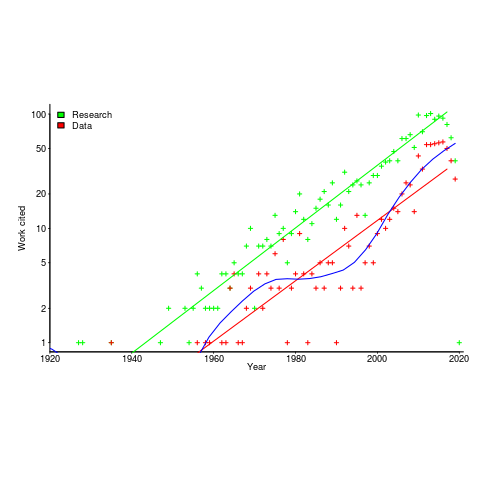
I claim that my evidence-based software engineering book contains all the useful publicly available software engineering data. The plot below shows the number of papers cited (green) and data available (red), per year; with fitted exponential regression models, and a piecewise regression fit to the data (blue) (code+data).
The citations+date include works that are not written by people involved in software engineering research, e.g., psychology, economics and ecology. For the time being I’m assuming that these non-software engineering researchers contribute a fixed percentage per year (the BibTeX file is available if anybody wants to do the break-down)
The two straight line fits are roughly parallel, and show an exponential growth over the years.
The piecewise regression (blue, loess was used) shows that the rate of growth in research data leveled-off in the late 1970s and only started to pick up again in the 1990s.
The dip in counts during the last few years is likely to be the result of me not having yet located all the recent empirical research.
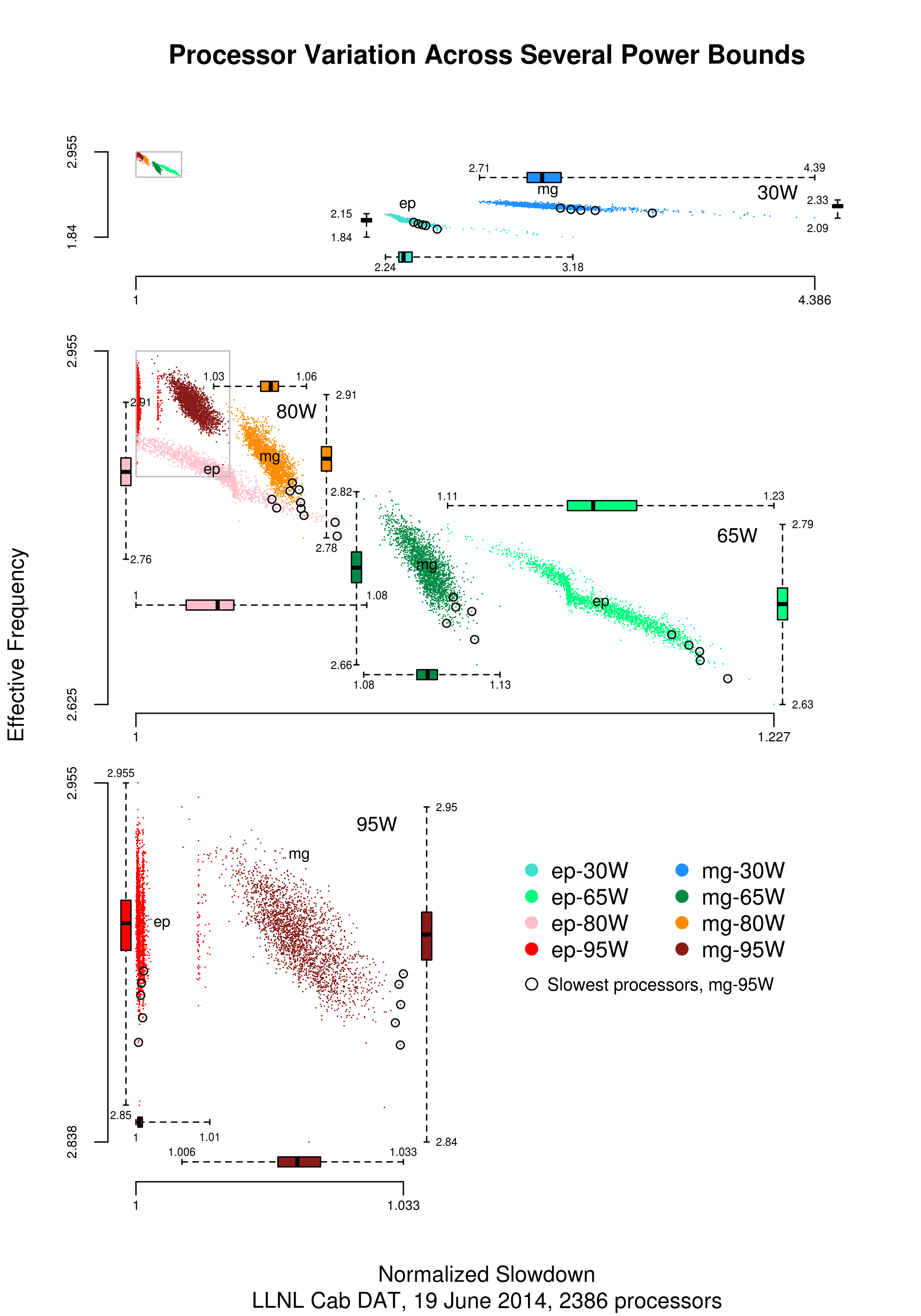
Every microprocessor is different, random variations in the manufacturing process result in transistors, and the connections between them, being fabricated with more/less atoms. An atom here and there makes very little difference when components are built from millions, or even thousands, of atoms. The width of the connections between transistors in modern devices might only be a dozen or so atoms, and an atom here and there can have a noticeable impact.
How does an atom here and there affect performance? Don’t all processors, of the same product, clocked at the same frequency deliver the same performance?
Yes they do, an atom here or there does not cause a processor to execute more/less instructions at a given frequency. But an atom here and there changes the thermal characteristics of processors, i.e., causes them to heat up faster/slower. High performance processors will reduce their operating frequency, or voltage, to prevent self-destruction (by overheating).
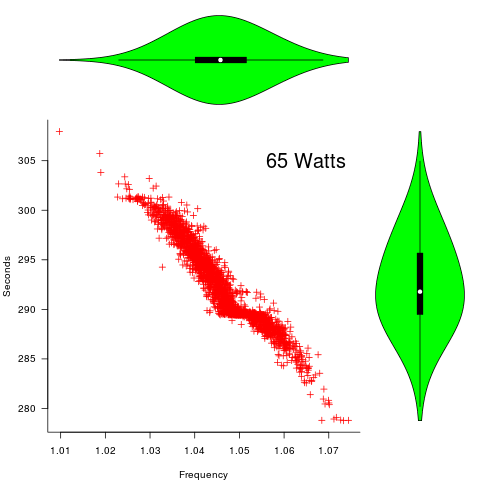
Processors operating within the same maximum power budget (say 65 Watts) may execute more/less instructions per second because they have slowed themselves down.
Some years ago I spotted a great example of ‘identical’ processor performance variation, and the author of the example, Barry Rountree, kindly sent me the data. In the weeks before Christmas I finally got around to including the data in my evidence-based software engineering book. Unfortunately I could not figure out what was what in the data (relearning an important lesson: make sure to understand the data as soon as it arrives), thankfully Barry came to the rescue and spent some time doing software archeology to figure out the data.
The original plots showed frequency/time data of 2,386 Intel Sandy Bridge XEON processors (in a high performance computer at the Lawrence Livermore National Laboratory) executing the EP benchmark (the data also includes measurements from the MG benchmark, part of the NAS Parallel benchmark) at various maximum power limits (see plot at end of post, which is normalised based on performance at 115 Watts). The plot below shows frequency/time for a maximum power of 65 Watts, along with violin plots showing the spread of processors running at a given frequency and taking a given number of seconds (my code, code+data on Barry’s github repo):
The expected frequency/time behavior is for processors to lie along a straight line running from top left to bottom right, which is roughly what happens here. I imagine (waving my software arms about) the variation in behavior comes from interactions with the other hardware devices each processor is connected to (e.g., memory, which presumably have their own temperature characteristics). Memory performance can have a big impact on benchmark performance. Some of the other maximum power limits have very different, and benchmark, measurements have very different characteristics (see below).
Intel’s Sandy Bridge is now around seven years old, and the number of atoms used to fabricate transistors and their connectors has shrunk and shrunk. An atom here and there is likely to produce even more variation in the performance of today’s processors.
Over the last few months we have seen how we can use a sequence of Householder transformations followed by a sequence of shifted Givens rotations to efficiently find the spectral decomposition of a symmetric real matrix M, formed from a matrix V and a diagonal matrix Λ satisfying
M × V = V × Λ
implying that the columns of V are the unit eigenvectors of M and their associated elements on the diagonal of Λ are their eigenvalues so that
V × VT = I
where I is the identity matrix, and therefore
M = V × Λ × VT
From a mathematical perspective the combination of Householder transformations and shifted Givens rotations is particularly appealing, converging on the spectral decomposition after relatively few matrix multiplications, but from an implementation perspective using ak.matrix multiplication operations is less than satisfactory since it wastefully creates new ak.matrix objects at each step and so in this post we shall start to see how we can do better.
 . What is the probability of the statement on the next line being a
. What is the probability of the statement on the next line being a