Derek Jones from The Shape of Code
A step change in the approach to updates and additions to the C++ Standard occurred at the recent WG21 meeting, or rather a change that has been kind of going on for a few meetings has been documented and discussed. Two bullet points at the start of “C++ Stability, Velocity, and Deployment Plans [R2]”, grab reader’s attention:
â— Is C++ a language of exciting new features?
â— Is C++ a language known for great stability over a long period?
followed by the proposal (which was agreed at the meeting): “The Committee should be willing to consider the design / quality of proposals even if they may cause a change in behavior or failure to compile for existing code.”
We have had 30 years of C++/C compatibility (ok, there have been some nibbling around the edges over the last 15 years). A remarkable achievement, thanks to Bjarne Stroustrup over 30+ years and 64 full-week standards’ meetings (also, Tom Plum and Bill Plauger were engaged in shuttle diplomacy between WG14 and WG21).
The C/C++ superset/different issue has a long history.
In the late 1980s SC22 (the top-level ISO committee for programming languages) asked WG14 (the C committee) whether a standard should be created for C++, and if so did WG14 want to create it. WG14 considered the matter at its April 1989 meeting, and replied that in its view a standard for C++ was worth considering, but that the C committee were not the people to do it.
In 1990, SC22 started a study group to look into whether a working group for C++ should be created and in the U.S. X3 (the ANSI committee responsible for Information processing systems) set up X3J16. The showdown meeting of what would become WG21, was held in London, March 1992 (the only ISO C++ meeting I have attended).
The X3J16 people were in London for the ISO meeting, which was heated at times. The two public positions were: 1) work should start on a standard for C++, 2) C++ was not yet mature enough for work to start on a standard.
The, not so public, reason given for wanting to start work on a standard was to stop, or at least slow down, changes to the language. New releases, rumored and/or actual, of Cfront were frequent (in a pre-Internet time sense). Writing large applications in a version of C++ that was replaced with something sightly different six months later was has developers in large companies pulling their hair out.
You might have thought that compiler vendors would be happy for the language to be changing on a regular basis; changes provide an incentive for users to pay for compiler upgrades. In practice the changes were so significant that major rework was needed by somebody who knew what they were doing, i.e., expensive people had to be paid; vendors were more used to putting effort into marketing minor updates. It was claimed that implementing a C++ compiler required seven times the effort of implementing a C compiler. I have no idea how true this claim might have been (it might have been one vendor’s approximate experience). In the 1980s everybody and his dog had their own C compiler and most of those who had tried, had run into a brick wall trying to implement a C++ compiler.
The stop/slow down changing C++ vs. let C++ “fulfill its destiny” (a rallying call from the AT&T rep, which the whole room cheered) finally got voted on; the study group became a WG (I cannot tell you the numbers; the meeting minutes are not online and I cannot find a paper copy {we had those until the mid/late-90s}).
The creation of WG21 did not have the intended effect (slowing down changes to the language); Stroustrup joined the committee and C++ evolution continued apace. However, from the developers’ perspective language change did slow down; Cfront changes stopped because its code was collapsing under its own evolutionary weight and usable C++ compilers became available from other vendors (in the early days, Zortech C++ was a major boost to the spread of usage).
The last WG21 meeting had 140 people on the attendance list; they were not all bored consultants looking for a creative outlet (i.e., exciting new features), but I’m sure many would be happy to drop the ball-and-chain (otherwise known as C compatibility).
I think there will be lots of proposals that will break C compatibility in one way or another and some will it into a published standard. The claim will be that the changes will make life easier for future C++ developers (a claim made by proponents of every language, for which there is zero empirical evidence). The only way of finding out whether a change has long term benefit is to wait a long time and see what happens.
The interesting question is how C++ compiler vendors will react to breaking changes in the language standard. There are not many production compilers out there these days, i.e., not a lot of competition. What incentive does a compiler vendor have to release a version of their compiler that will likely break existing code? Compiler validation, against a standard, is now history.
If WG21 make too many breaking changes, they could find C++ vendors ignoring them and developers asking whether the ISO C++ standards’ committee is past its sell by date.
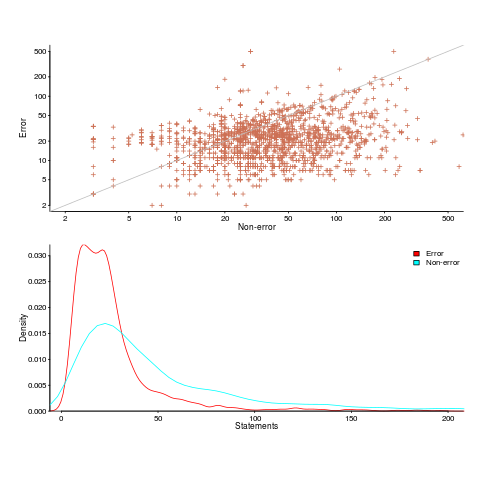
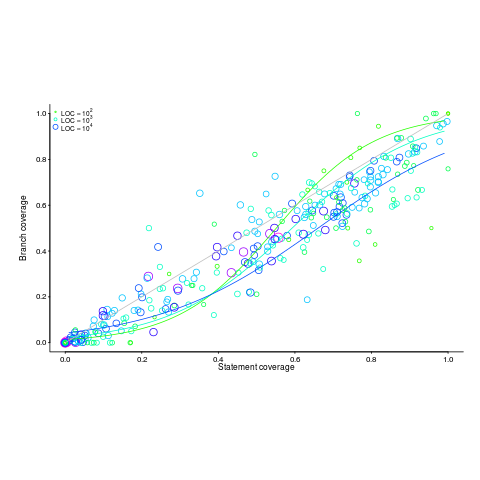
 paths.
paths.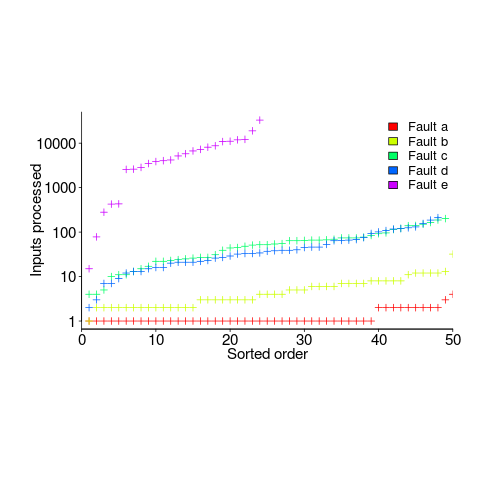

![S_{sd-est}=sqrt{f_2 [0.25k^2 ({f_1}/{f_2} )^4+k^2 ({f_1}/{f_2} )^3+0.5k ({f_1}/{f_2} )^2 ]}](http://shape-of-code.coding-guidelines.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_971.5_9eaa74a0e52ef66cad3146183e24b04f.png "S_{sd-est}=sqrt{f_2 [0.25k^2 ({f_1}/{f_2} )^4+k^2 ({f_1}/{f_2} )^3+0.5k ({f_1}/{f_2} )^2 ]}")
 is the estimated number of distinct faults,
is the estimated number of distinct faults,  the observed number of distinct faults,
the observed number of distinct faults,  the total number of faults,
the total number of faults,  the number of distinct faults that occurred once,
the number of distinct faults that occurred once,  the number of distinct faults that occurred twice,
the number of distinct faults that occurred twice,  .
.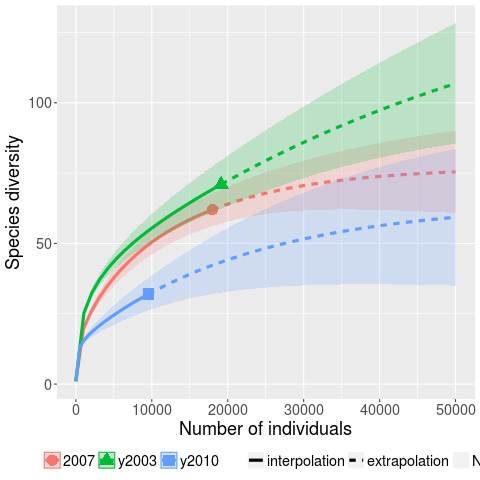
 , or
, or 
 (values taken from the first column of numbers above).
(values taken from the first column of numbers above). , while for
, while for  . So
. So }") , i.e., between 2.2 and 4.9 (the multiplication by 1.96 is used to give a 95% confidence interval); the
, i.e., between 2.2 and 4.9 (the multiplication by 1.96 is used to give a 95% confidence interval); the }") , between 0.3 and 0.6.
, between 0.3 and 0.6.