Andy Balaam from Andy Balaam's Blog
For when git status is not enough, I wrote git what:
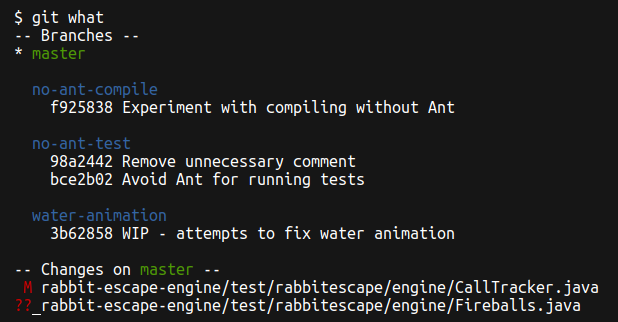
If you often have a few branches on the go, it could be useful.
Aggregating coding blogs
Andy Balaam from Andy Balaam's Blog
For when git status is not enough, I wrote git what:
If you often have a few branches on the go, it could be useful.
Andy Balaam from Andy Balaam's Blog
Series: asyncio basics, large numbers in parallel, parallel HTTP requests, adding to stdlib
I’ve been working on how to make a very large number of HTTP requests using Python’s asyncio and aiohttp.
PaweÅ‚ Miech’s post Making 1 million requests with python-aiohttp taught me how to think about this, and got us a long way, with 1 million requests running in a reasonable time, but I need to go further.
PaweÅ‚’s approach limits the number of requests that are in progress, but it uses an unbounded amount of memory to hold the futures that it wants to execute.
We can avoid using unbounded memory by using the limited_as_completed function I outined in my previous post.
We have a server program “server”:
(Note it differs from PaweÅ‚’s version because I am using an older version of aiohttp which has fewer convenient features.)
#!/usr/bin/env python3.5
from aiohttp import web
import asyncio
import random
async def handle(request):
await asyncio.sleep(random.randint(0, 3))
return web.Response(text="Hello, World!")
async def init():
app = web.Application()
app.router.add_route('GET', '/{name}', handle)
return await loop.create_server(
app.make_handler(), '127.0.0.1', 8080)
loop = asyncio.get_event_loop()
loop.run_until_complete(init())
loop.run_forever()
This just responds “Hello, World!” to every request it receives, but after an artificial delay of 0-3 seconds.
As a baseline, we have a synchronous client “client-sync”:
#!/usr/bin/env python3.5
import requests
import sys
url = "http://localhost:8080/{}"
for i in range(int(sys.argv[1])):
requests.get(url.format(i)).text
This waits for each request to complete before making the next one. Like the other clients below, it takes the number of requests to make as a command-line argument.
Copied mostly verbatim from Making 1 million requests with python-aiohttp we have an async client “client-async-sem” that uses a semaphore to restrict the number of requests that are in progress at any time to 1000:
#!/usr/bin/env python3.5
from aiohttp import ClientSession
import asyncio
import sys
limit = 1000
async def fetch(url, session):
async with session.get(url) as response:
return await response.read()
async def bound_fetch(sem, url, session):
# Getter function with semaphore.
async with sem:
await fetch(url, session)
async def run(session, r):
url = "http://localhost:8080/{}"
tasks = []
# create instance of Semaphore
sem = asyncio.Semaphore(limit)
for i in range(r):
# pass Semaphore and session to every GET request
task = asyncio.ensure_future(bound_fetch(sem, url.format(i), session))
tasks.append(task)
responses = asyncio.gather(*tasks)
await responses
loop = asyncio.get_event_loop()
with ClientSession() as session:
loop.run_until_complete(asyncio.ensure_future(run(session, int(sys.argv[1]))))
The new client I am presenting here uses limited_as_completed from the previous post. This means it can make a generator that provides the futures to wait for as they are needed, instead of making them all at the beginning.
It is called “client-async-as-completed”:
#!/usr/bin/env python3.5
from aiohttp import ClientSession
import asyncio
from itertools import islice
import sys
def limited_as_completed(coros, limit):
futures = [
asyncio.ensure_future(c)
for c in islice(coros, 0, limit)
]
async def first_to_finish():
while True:
await asyncio.sleep(0)
for f in futures:
if f.done():
futures.remove(f)
try:
newf = next(coros)
futures.append(
asyncio.ensure_future(newf))
except StopIteration as e:
pass
return f.result()
while len(futures) > 0:
yield first_to_finish()
async def fetch(url, session):
async with session.get(url) as response:
return await response.read()
limit = 1000
async def print_when_done(tasks):
for res in limited_as_completed(tasks, limit):
await res
r = int(sys.argv[1])
url = "http://localhost:8080/{}"
loop = asyncio.get_event_loop()
with ClientSession() as session:
coros = (fetch(url.format(i), session) for i in range(r))
loop.run_until_complete(print_when_done(coros))
loop.close()
Again, this limits the number of requests to 1000.
Finally, we have a test runner script called “timed”:
#!/usr/bin/env bash ./server & sleep 1 # Wait for server to start /usr/bin/time --format "Memory usage: %MKB\tTime: %e seconds" "$@" # %e Elapsed real (wall clock) time used by the process, in seconds. # %M Maximum resident set size of the process in Kilobytes. kill %1
This runs each process, ensuring the server is restarted each time it runs, and prints out how long it took to run, and how much memory it used.
When making only 10 requests, the async clients worked faster because they launched all the requests simultaneously and only had to wait for the longest one (3 seconds). The memory usage of all three clients was fine:
$ ./timed ./client-sync 10 Memory usage: 20548KB Time: 15.16 seconds $ ./timed ./client-async-sem 10 Memory usage: 24996KB Time: 3.13 seconds $ ./timed ./client-async-as-completed 10 Memory usage: 23176KB Time: 3.13 seconds
When making 100 requests, the synchronous client was very slow, but all three clients worked eventually:
$ ./timed ./client-sync 100 Memory usage: 20528KB Time: 156.63 seconds $ ./timed ./client-async-sem 100 Memory usage: 24980KB Time: 3.21 seconds $ ./timed ./client-async-as-completed 100 Memory usage: 24904KB Time: 3.21 seconds
At this point let’s agree that life is too short to wait for the synchronous client.
When making 10000 requests, both async clients worked quite quickly, and both had increased memory usage, but the semaphore-based one used almost twice as much memory as the limited_as_completed version:
$ ./timed ./client-async-sem 10000 Memory usage: 77912KB Time: 18.10 seconds $ ./timed ./client-async-as-completed 10000 Memory usage: 46780KB Time: 17.86 seconds
For 1 million requests, the semaphore-based client took 25 minutes on my (32GB RAM) machine. It only used about 10% of my CPU, and it used a lot of memory (over 3GB):
$ ./timed ./client-async-sem 1000000 Memory usage: 3815076KB Time: 1544.04 seconds
Note: PaweÅ‚’s version only took 9 minutes on his laptop and used all his CPU, so I wonder whether I have made a mistake somewhere, or whether my version of Python (3.5.2) is not as good as a later one.
The limited_as_completed version ran in a similar amount of time but used 100% of my CPU, and used a much smaller amount of memory (162MB):
$ ./timed ./client-async-as-completed 1000000 Memory usage: 162168KB Time: 1505.75 seconds
Now let’s try 100 million requests. The semaphore-based version lasted 10 hours before it was killed by Linux’s OOM Killer, but it didn’t manage to make any requests in this time, because it creates all its futures before it starts making requests:
$ ./timed ./client-async-sem 100000000 Command terminated by signal 9
I left the limited_as_completed version over the weekend and it managed to succeed eventually:
$ ./timed ./client-async-as-completed 100000000 Memory usage: 294304KB Time: 150213.15 seconds
So its memory usage was still very bounded, and it managed to do about 665 requests/second over an extended period, which is almost identical to the throughput of the previous cases.
Making a million requests is usually enough, but when we really need to do a lot of work while keeping our memory usage bounded, it looks like an approach like limited_as_completed is a good way to go. I also think it’s slightly easier to understand.
In the next post I describe my attempt to get something like this added to the Python standard library.
Andy Balaam from Andy Balaam's Blog
By default, when you make a UTC date from a Unix timestamp in Python and print it in ISO format, it has no time zone:
$ python3 >>> from datetime import datetime >>> datetime.utcfromtimestamp(1496998804).isoformat() '2017-06-09T09:00:04'
Whenever you talk about a datetime, I think you should always include a time zone, so I find this problematic.
The solution is to mention the timezone explicitly when you create the datetime:
$ python3 >>> from datetime import datetime, timezone >>> datetime.fromtimestamp(1496998804, tz=timezone.utc).isoformat() '2017-06-09T09:00:04+00:00'
Note, including the timezone explicitly works the same way when creating a datetime in other ways:
$ python3 >>> from datetime import datetime, timezone >>> datetime(2017, 6, 9).isoformat() '2017-06-09T00:00:00' >>> datetime(2017, 6, 9, tzinfo=timezone.utc).isoformat() '2017-06-09T00:00:00+00:00'
Andy Balaam from Andy Balaam's Blog
Series: asyncio basics, large numbers in parallel, parallel HTTP requests, adding to stdlib
I am interested in running large numbers of tasks in parallel, so I need something like asyncio.as_completed, but taking an iterable instead of a list, and with a limited number of tasks running concurrently. First, let’s try to build something pretty much equivalent to asyncio.as_completed. Here is my attempt, but I’d welcome feedback from readers who know better:
# Note this is not a coroutine - it returns
# an iterator - but it crucially depends on
# work being done inside the coroutines it
# yields - those coroutines empty out the
# list of futures it holds, and it will not
# end until that list is empty.
def my_as_completed(coros):
# Start all the tasks
futures = [asyncio.ensure_future(c) for c in coros]
# A coroutine that waits for one of the
# futures to finish and then returns
# its result.
async def first_to_finish():
# Wait forever - we could add a
# timeout here instead.
while True:
# Give up control to the scheduler
# - otherwise we will spin here
# forever!
await asyncio.sleep(0)
# Return anything that has finished
for f in futures:
if f.done():
futures.remove(f)
return f.result()
# Keep yielding a waiting coroutine
# until all the futures have finished.
while len(futures) > 0:
yield first_to_finish()
The above can be substituted for asyncio.as_completed in the code that uses it in the first article, and it seems to work. It also makes a reasonable amount of sense to me, so it may be correct, but I’d welcome comments and corrections.
my_as_completed above accepts an iterable and returns a generator producing results, but inside it starts all tasks concurrently, and stores all the futures in a list. To handle bigger lists we will need to do better, by limiting the number of running tasks to a sensible number.
Let’s start with a test program:
import asyncio
async def mycoro(number):
print("Starting %d" % number)
await asyncio.sleep(1.0 / number)
print("Finishing %d" % number)
return str(number)
async def print_when_done(tasks):
for res in asyncio.as_completed(tasks):
print("Result %s" % await res)
coros = [mycoro(i) for i in range(1, 101)]
loop = asyncio.get_event_loop()
loop.run_until_complete(print_when_done(coros))
loop.close()
This uses asyncio.as_completed to run 100 tasks and, because I adjusted the asyncio.sleep command to wait longer for earlier tasks, it prints something like this:
$ time python3 python-async.py Starting 47 Starting 93 Starting 48 ... Finishing 93 Finishing 94 Finishing 95 ... Result 93 Result 94 Result 95 ... Finishing 46 Finishing 45 Finishing 42 ... Finishing 2 Result 2 Finishing 1 Result 1 real 0m1.590s user 0m0.600s sys 0m0.072s
So all 100 tasks were completed in 1.5 seconds, indicating that they really were run in parallel, but all 100 were allowed to run at the same time, with no limit.
We can adjust the test program to run using our customised my_as_completed function, and pass in an iterable of coroutines instead of a list by changing the last part of the program to look like this:
async def print_when_done(tasks):
for res in my_as_completed(tasks):
print("Result %s" % await res)
coros = (mycoro(i) for i in range(1, 101))
loop = asyncio.get_event_loop()
loop.run_until_complete(print_when_done(coros))
loop.close()
But we get similar output to last time, with all tasks running concurrently.
To limit the number of concurrent tasks, we limit the size of the futures list, and add more as needed:
from itertools import islice
def limited_as_completed(coros, limit):
futures = [
asyncio.ensure_future(c)
for c in islice(coros, 0, limit)
]
async def first_to_finish():
while True:
await asyncio.sleep(0)
for f in futures:
if f.done():
futures.remove(f)
try:
newf = next(coros)
futures.append(
asyncio.ensure_future(newf))
except StopIteration as e:
pass
return f.result()
while len(futures) > 0:
yield first_to_finish()
We start limit tasks at first, and whenever one ends, we ask for the next coroutine in coros and set it running. This keeps the number of running tasks at or below limit until we start running out of input coroutines (when next throws and we don’t add anything to futures), then futures starts emptying until we eventually stop yielding coroutine objects.
I thought this function might be useful to others, so I started a little repo over here and added it: asyncioplus/limited_as_completed.py. Please provide merge requests and log issues to improve it – maybe it should be part of standard Python?
When we run the same example program, but call limited_as_completed instead of the other versions:
async def print_when_done(tasks):
for res in limited_as_completed(tasks, 10):
print("Result %s" % await res)
coros = (mycoro(i) for i in range(1, 101))
loop = asyncio.get_event_loop()
loop.run_until_complete(print_when_done(coros))
loop.close()
We see output like this:
$ time python3 python-async.py
Starting 1
Starting 2
...
Starting 9
Starting 10
Finishing 10
Result 10
Starting 11
...
Finishing 100
Result 100
Finishing 1
Result 1
real 0m1.535s
user 0m1.436s
sys 0m0.084s
So we can see that the tasks are still running concurrently, but this time the number of concurrent tasks is limited to 10.
To achieve a similar result using semaphores, see Python asyncio.semaphore in async-await function and Making 1 million requests with python-aiohttp.
It feels like limited_as_completed is more re-usable as an approach but I’d love to hear others’ thoughts on this. E.g. could/should I use a semaphore to implement limited_as_completed instead of manually holding a queue?
Andy Balaam from Andy Balaam's Blog
Series: asyncio basics, large numbers in parallel, parallel HTTP requests, adding to stdlib
Python 3’s asyncio module and the async and await keywords combine to allow us to do cooperative concurrent programming, where a code path voluntarily yields control to a scheduler, trusting that it will get control back when some resource has become available (or just when the scheduler feels like it). This way of programming can be very confusing, and has been popularised by Twisted in the Python world, and nodejs (among others) in other worlds.
I have been trying to get my head around the basic ideas as they surface in Python 3’s model. Below are some definitions and explanations that have been useful to me as I tried to grasp how it all works.
Futures and coroutines are both things that you can wait for.
You can make a coroutine by declaring it with async def:
import asyncio async def mycoro(number): print("Starting %d" % number) await asyncio.sleep(1) print("Finishing %d" % number) return str(number)
Almost always, a coroutine will await something such as some blocking IO. (Above we just sleep for a second.) When we await, we actually yield control to the scheduler so it can do other work and wake us up later, when something interesting has happened.
You can make a future out of a coroutine, but often you don’t need to. Bear in mind that if you do want to make a future, you should use ensure_future, but this actually runs what you pass to it – it doesn’t just create a future:
myfuture1 = asyncio.ensure_future(mycoro(1))
# Runs mycoro!
But, to get its result, you must wait for it – it is only scheduled in the background:
# Assume mycoro is defined as above
myfuture1 = asyncio.ensure_future(mycoro(1))
# We end the program without waiting for the future to finish
So the above fails like this:
$ python3 ./python-async.py
Task was destroyed but it is pending!
task: <Task pending coro=<mycoro() running at ./python-async:10>>
sys:1: RuntimeWarning: coroutine 'mycoro' was never awaited
The right way to block waiting for a future outside of a coroutine is to ask the event loop to do it:
# Keep on assuming mycoro is defined as above for all the examples
myfuture1 = asyncio.ensure_future(mycoro(1))
loop = asyncio.get_event_loop()
loop.run_until_complete(myfuture1)
loop.close()
Now this works properly (although we’re not yet getting any benefit from being asynchronous):
$ python3 python-async.py Starting 1 Finishing 1
To run several things concurrently, we make a future that is the combination of several other futures. asyncio can make a future like that out of coroutines using asyncio.gather:
several_futures = asyncio.gather(
mycoro(1), mycoro(2), mycoro(3))
loop = asyncio.get_event_loop()
print(loop.run_until_complete(several_futures))
loop.close()
The three coroutines all run at the same time, so this only takes about 1 second to run, even though we are running 3 tasks, each of which takes 1 second:
$ python3 python-async.py Starting 3 Starting 1 Starting 2 Finishing 3 Finishing 1 Finishing 2 ['1', '2', '3']
asyncio.gather won’t necessarily run your coroutines in order, but it will return a list of results in the same order as its input.
Notice also that run_until_complete returns the result of the future created by gather – a list of all the results from the individual coroutines.
To do the next bit we need to know how to call a coroutine from a coroutine. As we’ve already seen, just calling a coroutine in the normal Python way doesn’t run it, but gives you back a “coroutine object”. To actually run the code, we need to wait for it. When we want to block everything until we have a result, we can use something like run_until_complete but in an async context we want to yield control to the scheduler and let it give us back control when the coroutine has finished. We do that by using await:
import asyncio
async def f2():
print("start f2")
await asyncio.sleep(1)
print("stop f2")
async def f1():
print("start f1")
await f2()
print("stop f1")
loop = asyncio.get_event_loop()
loop.run_until_complete(f1())
loop.close()
This prints:
$ python3 python-async.py start f1 start f2 stop f2 stop f1
Now we know how to call a coroutine from inside a coroutine, we can continue.
We have seen that asyncio.gather takes in some futures/coroutines and returns a future that collects their results (in order).
If, instead, you want to get results as soon as they are available, you need to write a second coroutine that deals with each result by looping through the results of asyncio.as_completed and awaiting each one.
# Keep on assuming mycoro is defined as at the top
async def print_when_done(tasks):
for res in asyncio.as_completed(tasks):
print("Result %s" % await res)
coros = [mycoro(1), mycoro(2), mycoro(3)]
loop = asyncio.get_event_loop()
loop.run_until_complete(print_when_done(coros))
loop.close()
This prints:
$ python3 python-async.py Starting 1 Starting 3 Starting 2 Finishing 3 Result 3 Finishing 2 Result 2 Finishing 1 Result 1
Notice that task 3 finishes first and its result is printed, even though tasks 1 and 2 are still running.
asyncio.as_completed returns an iterable sequence of futures, each of which must be awaited, so it must run inside a coroutine, which must be waited for too.
The argument to asyncio.as_completed has to be a list of coroutines or futures, not an iterable, so you can’t use it with a very large list of items that won’t fit in memory.
Side note: if we want to work with very large lists, asyncio.wait won’t help us here – it also takes a list of futures and waits for all of them to complete (like gather), or, with other arguments, for one of them to complete or one of them to fail. It then returns two sets of futures: done and not-done. Each of these must be awaited to get their results, so:
asyncio.gather
# is roughly equivalent to:
async def mygather(*args):
ret = []
for r in (await asyncio.wait(args))[0]:
ret.append(await r)
return ret
I am interested in running very large numbers of tasks with limited concurrency – see the next article for how I managed it.
Andy Balaam from Andy Balaam's Blog
Series: Iterator, Iterator Wrapper, Non-1-1 Wrapper
Sometimes we want to write an iterator that consumes items from some underlying iterator but produces its own items slower than the items it consumes, like this:
ColonSep items("aa:foo::x");
// Prints "aa, foo, , x"
for(auto s : items)
{
std::cout << s << ", ";
}
When we pass a 9-character string (i.e. an iterator that yields 9 items) to ColonSep, above, we only repeat 4 times in our loop, because ColonSep provides an iterable range that yields one value for each whole word it finds in the underlying iterator of 9 characters.
To do something like this I'd recommend consuming the items of the underlying iterator early, so it is ready when requested with operator*. We also need our iterator class to hold on to the end of the underlying iterator as well as the current position.
First we need a small container to hold the next item we will provide:
struct maybestring
{
std::string value_;
bool at_end_;
explicit maybestring(const std::string value)
: value_(value)
, at_end_(false)
{}
explicit maybestring()
: value_("--error-past-end--")
, at_end_(true)
{}
};
A maybestring either holds the next item we will provide, or at_end_ is true, meaning we have reached the end of the underlying iterator and we will report that we are at the end ourself when asked.
Like the simpler iterators we have looked at, we still need a little container to return from the postincrement operator:
class stringholder
{
const std::string value_;
public:
stringholder(const std::string value) : value_(value) {}
std::string operator*() const { return value_; }
};
Now we are ready to write our iterator class, which always has the next value ready in its next_ member, and holds on to the current and end positions of the underlying iterator in wrapped_ and wrapped_end_:
class myit
{
private:
typedef std::string::const_iterator wrapped_t;
wrapped_t wrapped_;
wrapped_t wrapped_end_;
maybestring next_;
The constructor holds on the underlying iterator pointers, and immediately fills next_ with the next value by calling next_item passing in true to indicate that this is the first item:
public:
myit(wrapped_t wrapped, wrapped_t wrapped_end)
: wrapped_(wrapped)
, wrapped_end_(wrapped_end)
, next_(next_item(true))
{
}
// Previously provided by std::iterator
typedef int value_type;
typedef std::ptrdiff_t difference_type;
typedef int* pointer;
typedef int& reference;
typedef std::input_iterator_tag iterator_category;
next_item looks like this:
private:
maybestring next_item(bool first_time)
{
if (wrapped_ == wrapped_end_)
{
return maybestring(); // We are at the end
}
else
{
if (!first_time)
{
++wrapped_;
}
return read_item();
}
}
next_item recognises whether we've reached the end of the underlying iterator and saves the empty maybstring if so. Otherwise, it skips forward once (unless we are on the first element) and then calls read_item:
maybestring read_item()
{
std::string ret = "";
for (; wrapped_ != wrapped_end_; ++wrapped_)
{
char c = *wrapped_;
if (c == ':')
{
break;
}
ret += c;
}
return maybestring(ret);
}
read_item implements the real logic of looping through the underlying iterator and combining those values together to create the next item to provide.
The hard part of the iterator class is done, leaving only the more normal functions we must provide:
public:
value_type operator*() const
{
assert(!next_.at_end_);
return next_.value_;
}
bool operator==(const myit& other) const
{
// We only care about whether we are at the end
return next_.at_end_ == other.next_.at_end_;
}
bool operator!=(const myit& other) const { return !(*this == other); }
stringholder operator++(int)
{
assert(!next_.at_end_);
stringholder ret(next_.value_);
next_ = next_item(false);
return ret;
}
myit& operator++()
{
assert(!next_.at_end_);
next_ = next_item(false);
return *this;
}
}
Note that operator== is only concerned with whether or not we are an end iterator or not. Nothing else matters for providing correct iteration.
Our final bit of bookkeeping is the range class that allows our new iterator to be used in a for loop:
class ColonSep
{
private:
const std::string str_;
public:
ColonSep(const std::string str) : str_(str) {}
myit begin() { return myit(std::begin(str_), std::end(str_)); }
myit end() { return myit(std::end(str_), std::end(str_)); }
};
A lot of the code above is needed for all code that does this kind of job. Next time we'll look at how to use templates to make it useable in the general case.
Andy Balaam from Andy Balaam's Blog
My talk from ACCU Conference 2017 where I describe a tiny programming language I wrote:
Slides: How to write a programming language
Cell source code: github.com/andybalaam/cell