Andy Balaam from Andy Balaam's Blog
In which I make a square and a triangle bounce on a rectangle using Godot 3:
Godot version: v3.0.6.stable.official.8314054
Aggregating coding blogs
Andy Balaam from Andy Balaam's Blog
In which I make a square and a triangle bounce on a rectangle using Godot 3:
Godot version: v3.0.6.stable.official.8314054
Andy Balaam from Andy Balaam's Blog
Because the Rapsberry Pi uses a slightly older Python version, there is a special version of Graft for it.
Here’s how to get it:
sudo apt install python3-attr at-spi2-core
sudo apt install imagemagick
git clone https://github.com/andybalaam/graft.git cd graft git checkout raspberry-pi
./graft 'd+=10 S()'
If you’re looking for a fun way to start, why not try the worksheet “Tell a story by making animations with code”?
For more info, see Graft Raspberry Pi Setup.
Andy Balaam from Andy Balaam's Blog
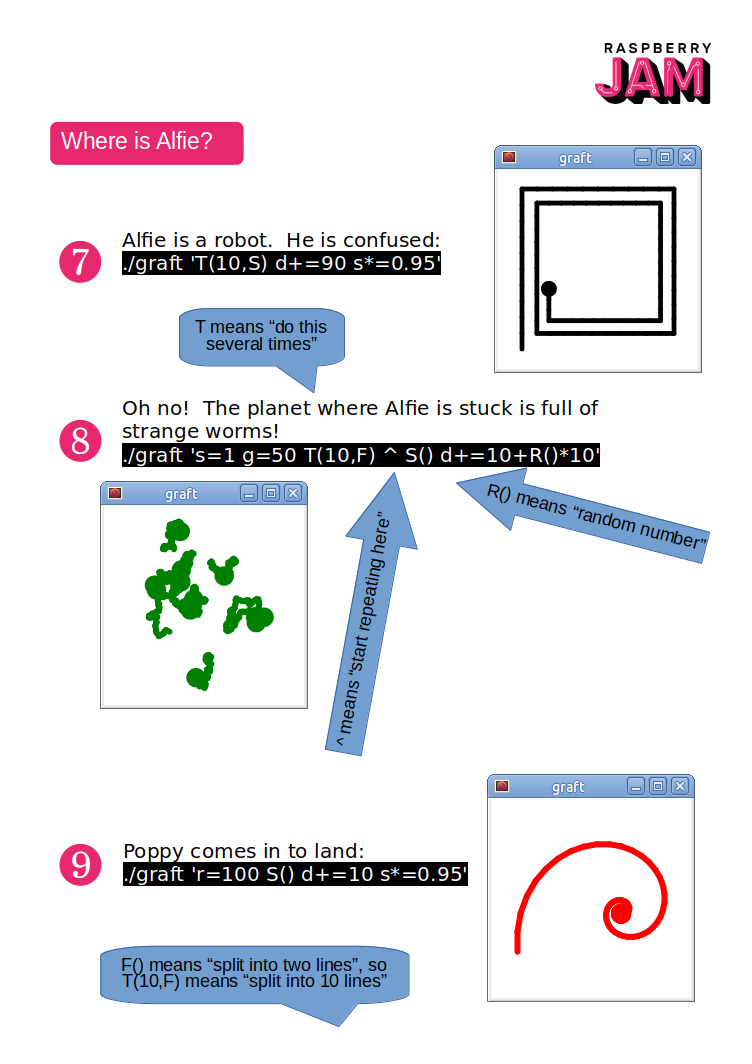
I’m running a workshop at the Egham Raspberry Jam on 21st October. The workshop will introduce my little animation language Graft. We will tell a story using animations that we created ourselves using code.
The worksheet for the workshop is here: PDF or ODP.
I reproduced it as images below.
Any feedback much appreciated.




Andy Balaam from Andy Balaam's Blog
Elm is unstable, so upgrading to the next version can be painful. Here’s what I needed to do to upgrade from 0.18 to 0.19.
The lack of Debug.crash is really, really painful, especially for a library like eeue56/elm-all-dict that has lots of invariants that are hard or impossible to enforce via the type system. On the other hand, if Elm can give a hard guarantee that there will be no runtime errors, this seems pretty cool. The problem is that some code may well have to return the wrong answer silently, instead of crashing, which could be much worse than crashing in some use-cases.
I was annoyed by the lack of more-than-3-part tuples, but even as I did the work to change my code, I saw it get better, so it’s hard to argue with.
The hardest part to work out was how to run the tests. Fortunately the tests themselves needed almost no changes. I just needed to do this:
rm -r tests/elm-stuff rm tests/elm-package.json sudo npm install -g elm-test@0.19.0-beta8 elm-test install elm-test
My next job is to check out the –optimize compiler flag, and the advice on making the code smaller and faster.
Andy Balaam from Andy Balaam's Blog
Recent Overload journal issues contain my new articles on How to Write a Programming Language.
Part 1: How to Write a Programming Language: Part 1, The Lexer
Part 2: How to Write a Programming Language: Part 2, The Parser
PDF of the latest issue: Overload 146 containing part 2.
This is all creative-commons licensed and developed in public at github.com/andybalaam/articles-how-to-write-a-programming-language
Andy Balaam from Andy Balaam's Blog
Groovy has lots of interesting syntax that can be used for domain-specific languages, such as Gradle build files, and Jenkinsfiles. I try to demystify the syntax tricks a bit so you have a chance to read and understand what the code is actually doing:
Slides and source code are available.
Andy Balaam from Andy Balaam's Blog
I am trying to practice documentation-driven development in Pepper3, so every time I start on an area, I will write documentation explaining how it works, and include examples that are automatically verified during the build.
I’ve started work on lexing, since you can’t do much before you do that, but in fact, of course, I need to have a command line interface before I can verify any of the examples, so I’m working on that too.
Lexing is the process that takes a stream of characters (e.g. from a file) and turns it into a stream of “tokens” that are chunks of code like a variable name, a number or a string. (There is more on lexing in my mini programming language, Cell.)
My thoughts so far about lexing are in lexing.md, and current ideas about command line interface are at command_line.md. All very much subject to change.
Headlines:
Andy Balaam from Andy Balaam's Blog
Series: Examples, Questions
My last post Examples of Pepper3 code was a reply to my friend’s email asking what it was all about. They replied with some questions, and I thought the questions and answers might shed some more light:
Questions!
Brilliant ones, thanks.
In general though you’ve said a lot about what Pepper can do without giving design decisions.
Yep, total brain dump.
Remind me again who this language is for :)
It’s a multi-paradigm (generic, functional, OO) language aimed at application programmers who want:
Can you assign floats to ints or vice versa?
Yes, but you shouldn’t.
If you’re setting types in code at the start of a file, is this only available in the main file? Are there multiple files per program? Can
you have libraries? If so, do these decide the functionality of their types in the library or does this only happen in the main file?
I haven’t totally decided – either by being enforced, or as a matter of style, you will generally do this once at the beginning of the program (and choose on the compiler command line to do it e.g. the debug way or the release way) and it will affect all of your code.
Libraries will be packaged as Pepper3 source code, so choices you make of the type of Int etc. will be reflected through the whole dependency tree. Cool, huh?
This is inspired by Python.
Can you group variables together into structs or similar?
Yes – it will be especially easy to make “value types”, and lots of default methods will be provided, that you will be strongly encouraged to use – e.g. copy and move operations. This is inspired by Elm.
Why are variables immutable by default but mutable with a special syntax? It’s the opposite of C++ const, but why that way around?
This is one of the “nudges” – immutable stuff is much easier to think about, and makes parallel stuff easier, and allows optimisations and so on, so turning it on by default means you have to choose to take the bad path, and are inclined to take the virtuous one. This is inspired by Haskell and Rust.
Why only allow assignments, function calls and operators? I’m sure you have good reasons.
To be as simple as possible, so you only have those things to learn and the rest can be understood by just reading the code. This is inspired by Python.
I wrote more of my (earlier) thoughts in this 4-post series, which is better thought through: Goodness in Programming Languages
Andy Balaam from Andy Balaam's Blog
Series: Examples, Questions
I have restarted my effort to make a new programming language that fits the way I like things. I haven’t pushed any code yet, but I have made a lot of progress in my head to understand what I want.
Here are some random examples that might get across some of the ways I am thinking:
// You code using general types like "Int" but you can set what
// they really are in the code (usually at the beginning), so
// if you plan to use native ints in the production code, it's
// a good idea to use:
Int = CheckedNativeInt;
// while in dev, since it will crash at runtime if you overflow.
// Then, in production when you're sure you have no errors,
// switch to an unchecked one:
Int = NativeInt;
// But, if you prefer correctness over efficiency, you can use
// mathematical integer that never overflows:
Int = ArbitrarySizeInt;
// Variables are immutable by default, so:
Int x = 4;
x = 3; // this is a compile error
// But this is OK
Mutable(Int) y = 6;
y = y + x;
// Notice that you can call functions that return types that you
// then use, like Mutable(Int) here.
// Generally, code can run at either compile time or run time.
// Code to do with types has to run at compile time.
// By default, other code runs at run time, but you can force
// it to run early if you want to.
// A main method looks like this - you get hold of e.g. stdout through
// a World instance - I try to avoid any global functions like print, or
// global variables like sys.stdout.
Auto main =
{:(World world)->Int
//...
};
// (Although note that Int, String etc. actually are global variables,
// which is a bit annoying)
// I wish the main method were simpler-looking. The only saving grace
// is that for simple examples you don't need a main method -
// Pepper3 just calculates the expression you provide in your file and
// prints it out.
// Expressions in curly brackets are lambda functions, so:
{3};
// is a function taking no arguments, returning 3, and:
{:(Int x)
x * 2
};
// is a function that doubles a value.
Obviously, we can tie functions to names:
Auto dbl =
{:(Int x)
x * 2
};
// Meaning we can call dbl like this:
dbl(4);
// Auto is a magic word to say ("use type inference"), so
// this is equivalent to the above:
fn([Int]->Int) dbl =
{:(Int x)
x * 2
};
// Because {} makes an anon function, things like "for" can be
// functions instead of keywords.
for(range(3), {:(Int x)
world.stdout.println(to(String)(x));
});
// As far as possible, Pepper3 will only contain assignment statements:
String s = "xx";
// and expressions containing function calls and operators:
dbl(3) + 6;
// This means we can make our own constructs like a different type of
// for loop, which would need a new keyword in some languages:
Auto parallel_for = import(multiprocess.parallel_for);
Andy Balaam from Andy Balaam's Blog
My OpenMarket colleagues and I ran a workshop at TECH(K)NOW Day on how to write your own programming language:

A big thank you to my colleagues from OpenMarket who volunteered to help: Rowan, Jenny, Zach, James and Elliot.

An extra thank you to Zach and Elliott for their impromptu help on the information desk for attendees:

Hopefully the attendees enjoyed it and learned a bit:
Making own programming language @TECHKNOWDay pic.twitter.com/jfUFHq7iO3
— 4theLoveOfCode (@4theLoveOfCode) October 10, 2017
It was an amazing workshop thank you @andybalaam
— 4theLoveOfCode (@4theLoveOfCode) October 10, 2017
You can find the workshop slides, the full code, info about another simple language called Cell, and lots more links here: github.com/andybalaam/videos-write-your-own-language, my blog at artificialworlds.net/blog, and follow me on twitter @andybalaam.
Thanks to OpenMarket for supporting us in running this workshop!
At @OpenMarket we are honoured to support the excellent work of @WomenWhoCode’s @TECHKNOWDay and celebrate #AdaLovelaceDay & #womenintech https://t.co/udYXTLjOqL
— OpenMarket (@openmarket) October 10, 2017