Derek Jones from The Shape of Code
Thanks to Darwin, the world is full of people who think that evolution, in nature, works by: natural selection, or the survival of the fittest. I thought this until I read “Good Enough: The Tolerance for Mediocrity in Nature and Society” by Daniel Milo.
Milo makes a very convincing case that nature actually works by: natural elimination, or the survival of the good enough.
Why might Darwin have gone with natural selection in his book, On the Origin of Species? Milo makes the point that the only real evidence that Darwin had to work with was artificial selection, that is the breeding of farm animals and domestic pets to select for traits that humans found desirable. Darwin’s visit to the Galápagos islands triggered a way of thinking, it did not provide him with the evidence he needed; Darwin’s Finches have become a commonly cited example of natural selection at work, but while Darwin made the observations it was not until 80 years later that somebody else spotted their relevance.
The Origin of Species, or to use its full title: “On the Origin of Species by means of natural selection, or the preservation of favored races in the struggle for life.” is full of examples and terminology relating to artificial selection.
Natural selection, or natural elimination, isn’t the result the same?
Natural selection implies an optimization process, e.g., breeders selecting for a strain of cows that produce the most milk.
Natural elimination is a good enough process, i.e., a creature needs a collection of traits that are good enough for them to create the next generation.
A long-standing problem with natural selection is that it fails to explain the diversity present in a natural population of some breed of animal (there is very little diversity in each breed of farm animal, they have been optimized for consistency). Diversity is not a problem for natural elimination, which does not reduce differences in its search for fitness.
The diversity produced as a consequence of natural elimination creates a population containing many neutral traits (i.e., characteristics that have no positive or negative impact on continuing survival). When a significant change in the environment occurs, one or more of the neutral traits may suddenly have positive or negative survival consequences; the creatures with the positive traits have opportunity time to adapt to the changed environment. A population whose members possess a diverse range of neutral traits has a higher chance of long-term survival than a population where diversity has been squeezed in the quest for the fittest.
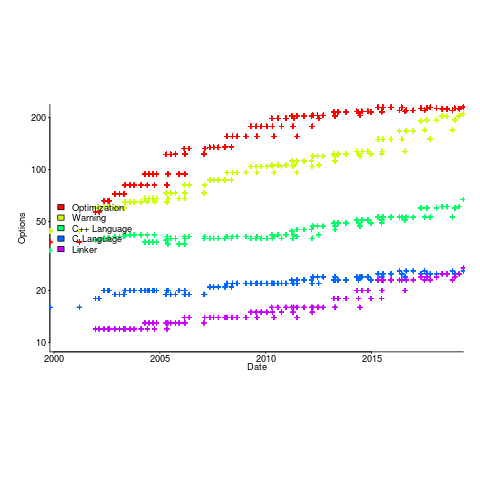
I think that natural elimination also applies within software ecosystems. Commercial products survive if enough customers buy them, software developers need good enough know-how to get the job done.
I’m sure customers would prefer software ecosystems to operate on the principle of survival of the fittest (it reduces their costs). Over the long term is society best served by diverse software ecosystems or softwaremonocultures? Diversity is a way of encouraging competition, but over time there is diminishing returns on the improvements.