Simon Brand from Simon Brand
This post is also available at the Microsoft Visual C++ Team Blog
C++17 merged in a paper called Guaranteed copy elision through simplified value categories. The changes mandate that no copies or moves take place in some situations where they were previously allowed, e.g.:
struct non_moveable {
non_moveable() = default;
non_moveable(non_moveable&&) = delete;
};
non_moveable make() { return {}; }
non_moveable x = make(); //compiles in C++17, error in C++11/14
You can see this behavior in compiler versions Visual Studio 2017 15.6, Clang 4, GCC 7, and above.
Despite the name of the paper and what you might read on the Internet, the new rules do not guarantee copy elision. Instead, the new value category rules are defined such that no copy exists in the first place. Understanding this nuance gives a deeper understanding of the current C++ object model, so I will explain the pre-C++17 rules, what changes were made, and how they solve real-world problems.
Value Categories
To understand the before-and-after, we first need to understand what value categories are (I’ll explain copy elision in the next section). Continuing the theme of C++ misnomers, value categories are not categories of values. They are characteristics of expressions. Every expression in C++ has one of three value categories: lvalue, prvalue (pure rvalue), or xvalue (eXpring value). There are then two parent categories: all lvalues and xvalues are glvalues, and all prvalues and xvalues are rvalues.
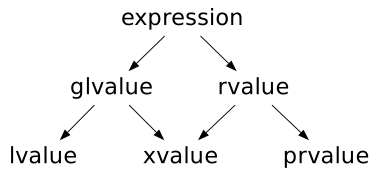
For an explanation of what these are, we can look at the standard (C++17 [basic.lval]/1):
- A glvalue ([generalised lvalue]) is an expression whose evaluation determines the identity of an object, bit-field, or function.
- A prvalue is an expression whose evaluation initializes an object or a bit-field, or computes the value of an operand of an operator, as specified by the context in which it appears.
- An xvalue is a glvalue that denotes an object or bit-field whose resources can be reused (usually because it is near the end of its lifetime).
- An lvalue is a glvalue that is not an xvalue.
- An rvalue is a prvalue or an xvalue.
Some examples:
std::string s;
s //lvalue: identity of an object
s + " cake" //prvalue: could perform initialization/compute a value
std::string f();
std::string& g();
std::string&& h();
f() //prvalue: could perform initialization/compute a value
g() //lvalue: identity of an object
h() //xvalue: denotes an object whose resources can be reused
struct foo {
std::string s;
};
foo{}.s //xvalue: denotes an object whose resources can be reused
C++11
What are the properties of the expression std::string{"a pony"}?
It’s a prvalue. Its type is std::string. It has the value "a pony". It names a temporary.
That last one is the key point I want to talk about, and it’s the real difference between the C++11 rules and C++17. In C++11, std::string{"a pony"} does indeed name a temporary. From C++11 [class.temporary]/1:
Temporaries of class type are created in various contexts: binding a reference to a prvalue, returning a prvalue, a conversion that creates a prvalue, throwing an exception, entering a handler, and in some initializations.
Let’s look at how this interacts with this code:
struct copyable {
copyable() = default;
copyable(copyable const&) { /*...*/ }
};
copyable make() { return {}; }
copyable x = make();
make() results in a temporary. This temporary will be moved into x. Since copyable has no move constructor, this calls the copy constructor. However, this copy is unnecessary since the object constructed on the way out of make will never be used for anything else. The standard allows this copy to be elided by constructing the return value at the call-site rather than in make (C++11 [class.copy]). This is called copy elision.
The unfortunate part is this: even if all copies of the type are elided, the constructor still must exist.
This means that if we instead have:
struct non_moveable {
non_moveable() = default;
non_moveable(non_moveable&&) = delete;
};
non_moveable make() { return {}; }
auto x = make();
then we get a compiler error:
<source>(7): error C2280: 'non_moveable::non_moveable(non_moveable &&)': attempting to reference a deleted function
<source>(3): note: see declaration of 'non_moveable::non_moveable'
<source>(3): note: 'non_moveable::non_moveable(non_moveable &&)': function was explicitly deleted
Aside from returning non-moveable types by value, this presents other issues:
- Use of Almost Always Auto style is prevented for immobile types:
auto x = non_moveable{}; //compiler error
- The language makes no guarantees that the constructors won’t be called (in practice this isn’t too much of a worry, but guarantees are more convincing than optional optimizations).
- If we want to support some of these use-cases, we need to write copy/move constructors for types which they don’t make sense for (and do what? Throw? Abort? Linker error?)
- You can’t pass non-moveable types to functions by value, in case you have some use-case which that would help with.
What’s the solution? Should the standard just say “oh, if you elide all copies, you don’t need those constructors� Maybe, but then all this language about constructing temporaries is really a lie and building an intuition about the object model becomes even harder.
C++17
C++17 takes a different approach. Instead of guaranteeing that copies will be elided in these cases, it changes the rules such that the copies were never there in the first place. This is achieved through redefining when temporaries are created.
As noted in the value category descriptions earlier, prvalues exist for purposes of initialization. C++11 creates temporaries eagerly, eventually using them in an initialization and cleaning up copies after the fact. In C++17, the materialization of temporaries is deferred until the initialization is performed.
That’s a better name for this feature. Not guaranteed copy elision. Deferred temporary materialization.
Temporary materialization creates a temporary object from a prvalue, resulting in an xvalue. The most common places it occurs are when binding a reference to or performing member access on a prvalue. If a reference is bound to the prvalue, the materialized temporary’s lifetime is extended to that of the reference (this is unchanged from C++11, but worth repeating). If a prvalue initializes a class type of the same type as the prvalue, then the destination object is initialized directly; no temporary required.
Some examples:
struct foo {
int i;
};
foo make();
auto& a = make(); //temporary materialized and lifetime-extended
auto&& b = make(); //ditto
foo{}.i //temporary materialized
auto c = make(); //no temporary materialized
That covers the most important points of the new rules. Now on to why this is actually useful past terminology bikeshedding and trivia to impress your friends.
Who cares?
I said at the start that understanding the new rules would grant a deeper understanding of the C++17 object model. I’d like to expand on that a bit.
The key point is that in C++11, prvalues are not “pure†in a sense. That is, the expression std::string{"a pony"} names some temporary std::string object with the contents "a pony". It’s not the pure notion of the list of characters “a ponyâ€. It’s not the Platonic ideal of “a ponyâ€.
In C++17, however, std::string{"a pony"} is the Platonic ideal of “a ponyâ€. It’s not a real object in C++’s object model, it’s some elusive, amorphous idea which can be passed around your program, only being given form when initializing some result object, or materializing a temporary. C++17’s prvalues are purer prvalues.
If this all sounds a bit abstract, that’s okay, but internalising this idea will make it easier to reason about aspects of your program. Consider a simple example:
struct foo {};
auto x = foo{};
In the C++11 model, the prvalue foo{} creates a temporary which is used to move-construct x, but the move is likely elided by the compiler.
In the C++17 model, the prvalue foo{} initializes x.
A more complex example:
std::string a() {
return "a pony";
}
std::string b() {
return a();
}
int main() {
auto x = b();
}
In the C++11 model, return "a pony"; initializes the temporary return object of a(), which move-constructs the temporary return object of b(), which move-constructs x. All the moves are likely elided by the compiler.
In the C++17 model, return "a pony"; initializes the result object of a(), which is the result object of b(), which is x.
In essence, rather than an initializer creating a series of temporaries which in theory move-construct a chain of return objects, the initializer is teleported to the eventual result object. In C++17, the code:
T a() { return /* expression */ ; }
auto x = a();
is identical to auto x = /* expression */;. For any T.
Closing
The “guaranteed copy elision†rules do not guarantee copy elision; instead they purify prvalues such that the copy doesn’t exist in the first place. Next time you hear or read about “guaranteed copy elisionâ€, think instead about deferred temporary materialization.