Derek Jones from The Shape of Code
What percentage of the budget for a bespoke hardware/software system is spent on software, compared to hardware?
The plot below has become synonymous with this question (without the red line, which highlights 1973), and is often used to claim that software costs are many times more than hardware costs.
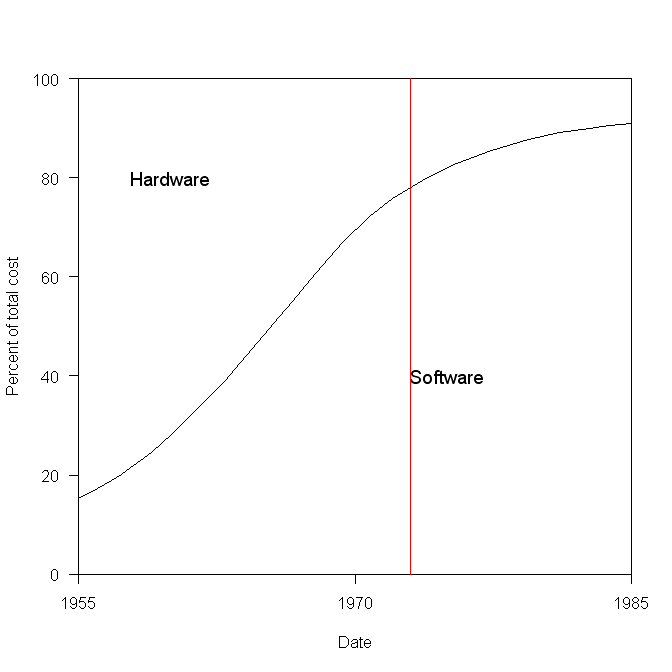
The paper containing this plot was published in 1973 (the original source is a Rome period report), and is an extrapolation of data I assume was available in 1973, into what was then the future. The software and hardware costs are for bespoke command and control systems delivered to the U.S. Air Force, not commercial off-the-shelf solutions or even bespoke commercial systems.
Does bespoke software cost many times more than the hardware it runs on?
I don’t have any data that might be used to answer this questions, to any worthwhile degree of accuracy. I know of situations where I believe the bespoke software did cost a lot more than the hardware, and I know of some where the hardware cost more (I have never been privy to exact numbers on large projects).
Where did the pre-1973 data come from?
The USAF funded the creation of lots of source code, and the reports cite hardware and software figures from 1972.
To summarise: the above plot is for USAF spending on bespoke command and control hardware and software, and is extrapolated from 1973 into the future.