Allan Kelly from Allan Kelly Associates

User Stories Masterclass, 29 June & Agile Estimating & Forecasting, 13 July – discounts below
I was once responsible for coaching a Product Owner called Jac. It was product owner for an “enterprise product†– a product sold to big companies to use internally. Sprint to sprint Jac got to decide what got done. In my book Product Owner authority went further: what was to be done in future sprints, what kind of things would be done in months to come, and the “roadmap†where the product was going. But… Jac seldom met customers, Jac might talk to them on the phone when they had a problem but Jac didn’t talk to the more senior people who signed the purchase orders.
Being an enterprise product there were consultants in the mix too: installing the product on site, configure the product, train customers and hold their hands. They went to customer sites and they met all sorts of people. Naturally the consultants had a view on what the product should do, what should be developed next and what should be done in coming months.
And all a consultant had to do was name a customer “Anna at Credit…†or “The CFO of first…. told me†and you could just see the product owner being undermined. I used to groan internally, I hated it – I hated it for my PO – but they were right.
When you meet customers you carry extra authority.
Last week I did a webinar entitled to Agile London entitled “Product Owner Common Mistakes†(the PDF). Guess what common mistake number #1 was?
(I also did a webinar with Adrian Reed entitled “Everything you ever wanted to know about the Product Owner but were afraid to ask†which was a great chat and audience Q&A session.)
Product Owner mistake #1: Not meeting customers
And here I mean Customers, and/or Users, and/or Stakeholders, I mean: people – and it is people – who have expectations, needs or wants for your product. Even if they don’t know your product could help address those needs and wants.
And when I say “meet,†well yes, I really would like you to meet them, shake them by the hand and share a coffee. I think you are both more likely to open up, share more and understand more. If possible spend some time observing them work.
I’m not stupid, I know we all work from home now, I know physical meetings are more difficult than ever so please substitute “meet†with Zoom, Skype, WhatsApp or plain old telephone. But as soon as you can get out and meet people.
In meeting people Product Owners get two big benefits.
The most obvious benefit is that Product Owners understand their customers and their needs better. They can learn how the product could help more, or where the product trips them up. They can learn how the product is beneficial and valuable and how that value might be increased.
Product Owners will also learn things they might not like to hear, things which might not be said over the telephone: where the product stinks, what alternatives might be considered and where the product gets in the way.
“what the customer buys is seldom what the company sells†Peter Drucker
People don’t like giving bad news and it is easier to hide such facts phone call, let alone in an e-mail.
The second benefit, as described in my opening story is authority and legitimacy.
Product Owners are specialists in what customer problems need solving, how enhancements to the product can add value and therefore what needs to be done to the product. They can only do that when they meet customers.
Meeting customers brings authority, one can say “Anna at Credit Bank told me…â€
Meeting customers brings legitimacy because most other people never interact with actual customers, or only interact with a small subset when they have problems.
And as my example shows: if a Product Owner is not meeting customers they leave themselves vulnerable to those who do. When someone else, like a consultant, comes along and says “Anna from … says… †they have authority, if the PO can not say “Mez from … had a different perspective…â€
Direct access to customers – speaking to them and visiting them – confers authority and legitimacy. Product Owners need that authority and the knowledge that comes with it.
User Stories Masterclass is running online again, 29 June NOW BOOKING
Use code BLOG_READER for 30% discount + 25% Early Bird discount
New online class: Agile Estimating & Forecasting, 13 July – NOW BOOKING
Use code BLOG_READER for 45% discount + 25% Early Bird discount
Subscribe to my blog newsletter and download Project Myopia for Free
The post Product Owner: meet they customer appeared first on Allan Kelly Associates.




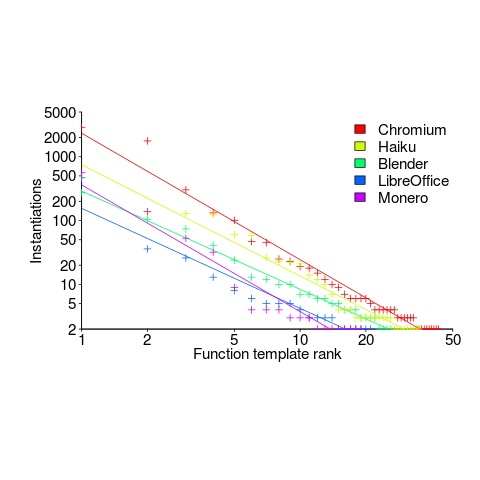
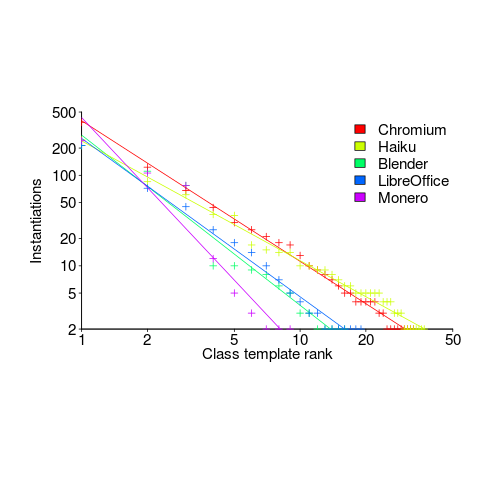
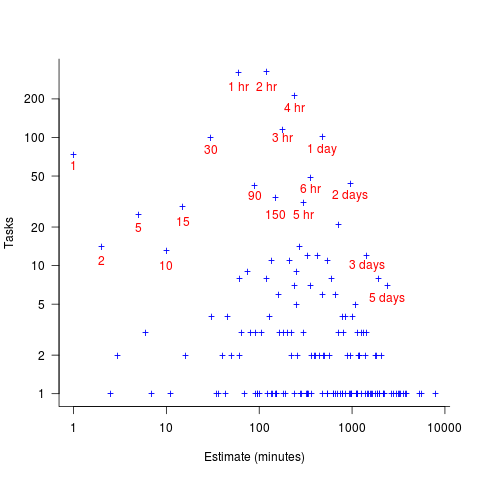

 had a much bigger impact than
had a much bigger impact than  . This was true for all the models I built using data for all Android/iOS Apps, and the exponent difference was always greater than two.
. This was true for all the models I built using data for all Android/iOS Apps, and the exponent difference was always greater than two. as a power-law.
as a power-law. varied by several orders of magnitude (which won’t come as a surprise to developers using earlier versions of Android).
varied by several orders of magnitude (which won’t come as a surprise to developers using earlier versions of Android).