Derek Jones from The Shape of Code
What are the processes involved in reasoning? While philosophers have been thinking about this question for several thousand years, psychologists have been running human reasoning experiments for less than a hundred years (things took off in the late 1960s with the Wason selection task).
Reasoning is a crucial ability for software developers, and I thought that there would be lots to learn from the cognitive psychologists research into reasoning. After buying all the books, and reading lots of papers, I realised that the subject was mostly convoluted rabbit holes individually constructed by tiny groups of researchers. The field of decision-making is where those psychologists interested in reasoning, and a connection to reality, hang-out.
Is there anything that can be learned from research into human reasoning (other than that different people appear to use different techniques, and some problems are more likely to involve particular techniques)?
A consistent result from experiments involving syllogistic reasoning is that subjects are more likely to agree that a conclusion they find believable follows from the premise (and are more likely to disagree with a conclusion they find unbelievable). The following is perhaps the most famous syllogism (the first two lines are known as the premise, and the last line is the conclusion):
All men are mortal.
Socrates is a man.
Therefore, Socrates is mortal.
Would anybody other than a classically trained scholar consider that a form of logic invented by Aristotle provides a reasonable basis for evaluating reasoning performance?
Given the importance of reasoning ability in software development, there ought to be some selection pressure on those who regularly write software, e.g., software developers ought to give a higher percentage of correct answers to reasoning problems than the general population. If the selection pressure for reasoning ability is not that great, at least software developers have had a lot more experience solving this kind of problem, and practice should improve performance.
The subjects in most psychology experiments are psychology undergraduates studying in the department of the researcher running the experiment, i.e., not the general population. Psychology is a numerate discipline, or at least the components I have read up on have a numeric orientation, and I have met a fair few psychology researchers who are decent programmers. Psychology undergraduates must have an above general-population performance on syllogism problems, but better than professional developers? I don’t think so, but then I may be biased.
A study by Winiger, Singmann, and Kellen asked subjects to specify whether the conclusion of a syllogism was valid/invalid/don’t know. The syllogisms used were some combination of valid/invalid and believable/unbelievable; examples below:
Believable Unbelievable
Valid
No oaks are jubs. No trees are punds.
Some trees are jubs. Some Oaks are punds.
Therefore, some trees Therefore, some oaks
are not oaks. are not trees.
Invalid
No tree are brops. No oaks are foins.
Some oaks are brops. Some trees are foins.
Therefore, some trees Therefore, some oaks
are not oaks. are not trees.
The experiment was run using an online crowdsource site, and 354 data sets were obtained.
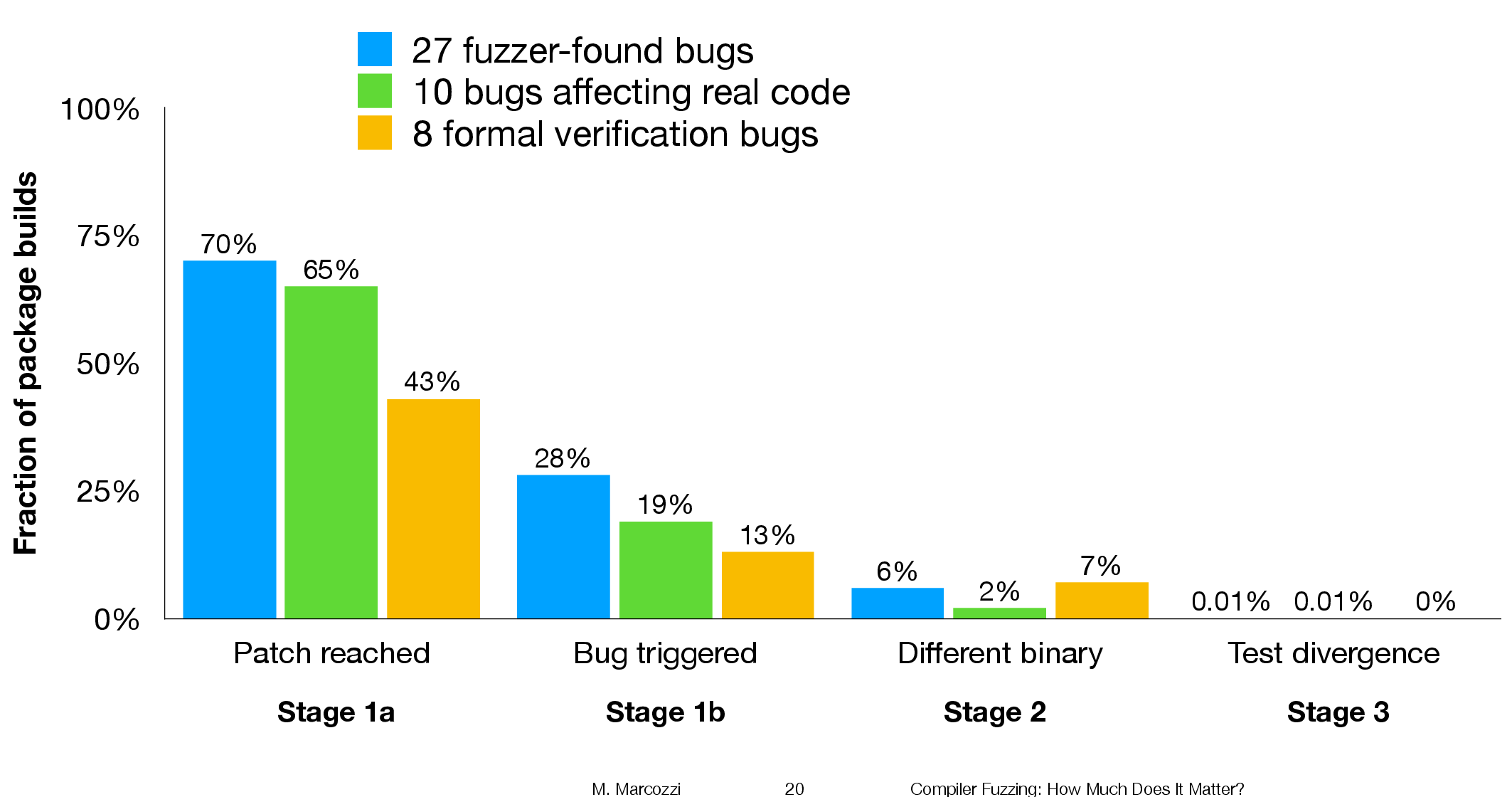
The plot below shows the impact of conclusion believability (red)/unbelievability (blue/green) on subject performance, when deciding whether a syllogism was valid (left) or invalid (right), (code+data):
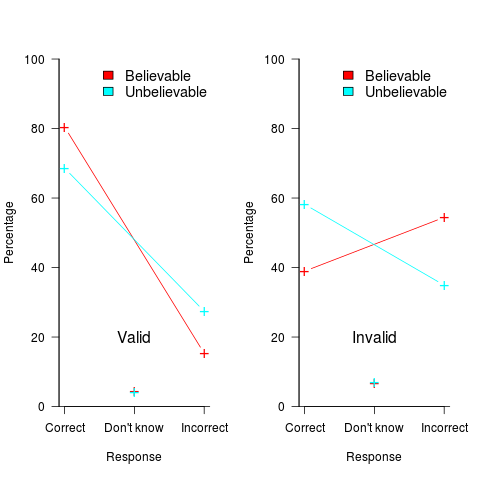
The believability of the conclusion biases the responses away/towards the correct answer (the error bars are tiny, and have not been plotted). Building a regression model puts numbers to the difference, and information on the kind of premise can also be included in the model.
Do professional developers exhibit such a large response bias (I would expect their average performance to be better)?
People tend to write fewer negative tests, than positive tests. Is this behavior related to the believability that certain negative events can occur?
Believability is an underappreciated coding issue.
Hopefully people will start doing experiments to investigate this issue 

 , while hyperbolic discounting has the form
, while hyperbolic discounting has the form  , where:
, where:  is a constant, and
is a constant, and  the period of time.
the period of time.
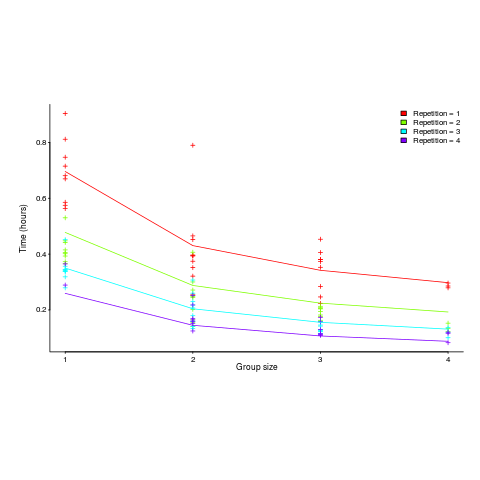
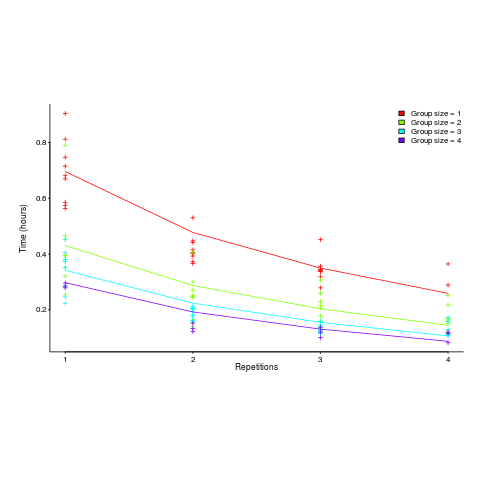
") applies, but the division by group-size was found by suck-it-and-see (in another post I found that
applies, but the division by group-size was found by suck-it-and-see (in another post I found that ![time = 0.16+ 0.53/{group size} - log(repetitions)*[0.1 + {0.22}/{group size}]](http://shape-of-code.coding-guidelines.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_980.5_b0d171bba046801a68ce5dc8ae1d6115.png "time = 0.16+ 0.53/{group size} - log(repetitions)*[0.1 + {0.22}/{group size}]")