Derek Jones from The Shape of Code
Learning is an integral part of writing software. What have psychologists figured out about the characteristics of human learning?
A study of memory, published in 1885, kicked off the start of modern psychology research. At the start of the 1900s, learning research was still closely tied to the study of the characteristics of what we now call working memory, e.g., measuring the time taken for subjects to correctly recall sequences of digits, nonsense syllables, words and prose. By the 1930s, learning was a distinct subject in its own right.
What is now known as the power law of learning was first proposed in 1926. Wikipedia is right to use the phrase power law of practice, since it is some measure of practice that appears in the power law of learning equation:  , where:
, where:  is the time taken to do the task,
is the time taken to do the task, is some measure of practice (such as the number of times the subject has performed the task), and
is some measure of practice (such as the number of times the subject has performed the task), and  ,
,  , and
, and  are constants fitted to the data.
are constants fitted to the data.
For the next 70 years some form of power law did a good job of fitting the learning data produced by researchers. Then in 1997 a paper pointed out that researchers were fitting aggregate data (i.e., one equation fitted to all subject data), and that an exponential equation was a better fit to individual subject response times:  . The power law appeared to be the result of aggregating the exponential response performance of multiple subjects; oops.
. The power law appeared to be the result of aggregating the exponential response performance of multiple subjects; oops.
What is the situation today, 25 years later? Do the subsystems of our brains produce a power law or exponential improvement in performance, with practice?
The problem with answering this question is that both equations can fit the available data quite well, with one being a technically better fit than the other for different datasets. The big difference between the two equations is in their tails, however, it is costly and time-consuming to obtain enough data to distinguish between them in this region.
When discussing learning in my evidence-based software engineering book, I saw no compelling reason to run counter to the widely cited power law, but I did tell readers about the exponential fit issue.
Studies of learnings have tended to use simple tasks; subjects are usually only available for a short time, and many task repetitions are needed to model the impact of learning. Simple tasks tend to be dominated by one primary activity, which means that subjects can focus their learning on this one activity.
Complicated tasks involve many activities, each potentially providing distinct learning opportunities. Which activities will a subject focus on improving, will the performance on one activity improve faster than others, will the approach chosen for one activity limit the performance on a second activity?
For a complicated task, the change in performance with amount of practice could be a lot more complicated than a single power law/exponential equation, e.g., there may be multiple equations with each associated with one or more activities.
In the previous paragraph, I was careful to say “could be a lot more complicated”. This is because the few datasets of organizational learning show a power law performance improvement, e.g., from 1936 we have the most cited study Factors Affecting the Cost of Airplanes, and the less well known but more interesting Liberty shipbuilding from the 1940s.
If the performance of something involving multiple people performing many distinct activities follows a power law improvement with practice, then the performance of an individual carrying out a complicated task might follow a simple equation; perhaps the combined form of many distinct simple learning activities is a simple equation.
Researchers are now proposing more complicated models of learning, along with fitting them to existing learning datasets.
Which equation should software developers use to model the learning process?
I continue to use a power law. The mathematics tend to be straight-forward, and it often gives an answer that is good enough (because the data fitted contains lots of variance). If it turned out that an exponential would be easier to work with, I would be happy to switch. Unless there is a lot of data in the tail, the difference between power law/exponent is usually not worth worrying about.
There are situations where I have failed to successfully add a learning (power law) component to a model. Was this because there was no learning present, or was the learning not well-fitted by a power law? I don’t know, and I cannot think of an alternative equation that might work, for these cases.
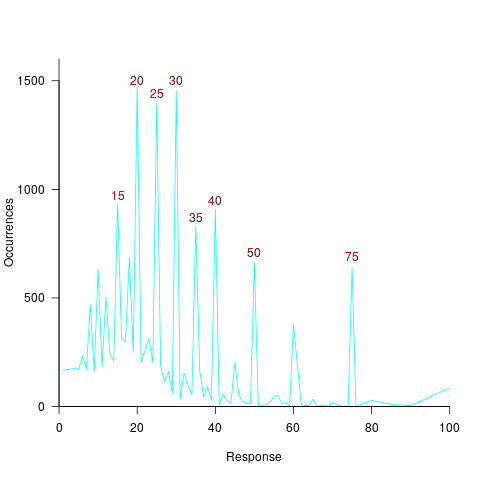
 (
(
 explains nearly all the variance present in the data.
explains nearly all the variance present in the data.
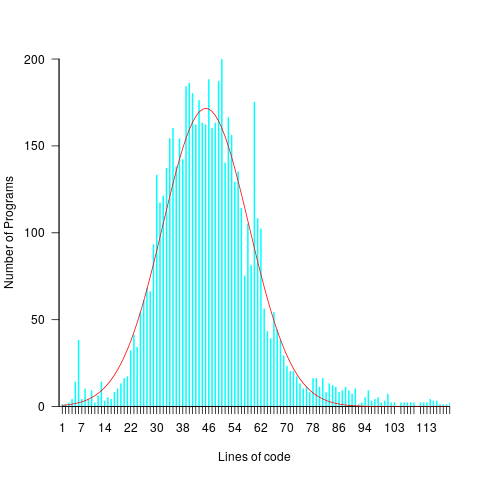
 , and red line a fitted regression model having the form
, and red line a fitted regression model having the form  (which explains just over 70% of the variance;
(which explains just over 70% of the variance; 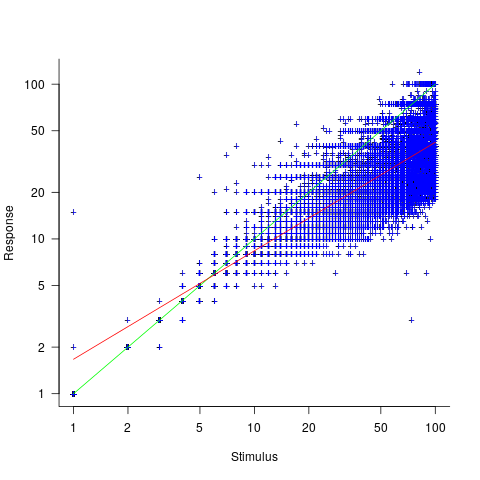
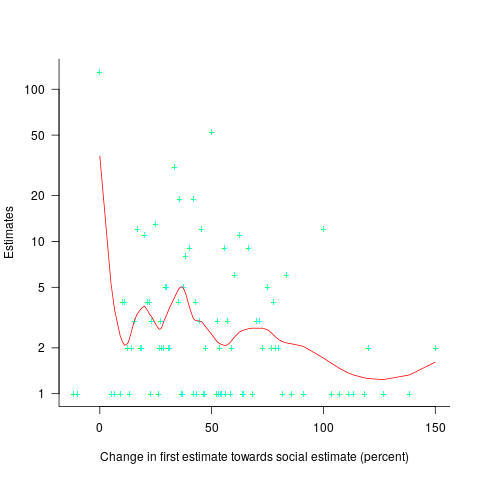
 , with
, with  varying between 0.65 and 1.57; more than a factor of two difference between subjects (this model explains just under 90% of the variance). This is a smaller range than the software estimation data, but with only six subjects there was less chance of a wider variation (
varying between 0.65 and 1.57; more than a factor of two difference between subjects (this model explains just under 90% of the variance). This is a smaller range than the software estimation data, but with only six subjects there was less chance of a wider variation (