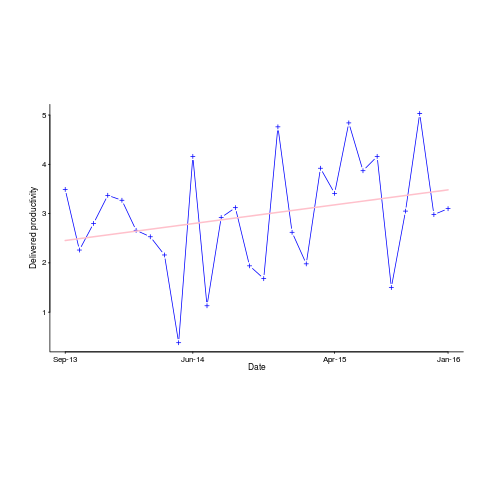
Derek Jones from The Shape of Code
There is a lot of source code available which is said to be open source. One definition of open source is software that has an associated open source license. Along with promoting open source, the Open Source Initiative (OSI) has a rigorous review process for open source licenses (so they say, I have no expertise in this area), and have become the major licensing brand in this area.
Analyzing the use of licenses in source files and packages has become a niche research topic. The majority of source files don’t contain any license information, and, depending on language, many packages don’t include a license either (see Understanding the Usage, Impact, and Adoption of Non-OSI Approved Licenses). There is some evolution in license usage, i.e., changes of license terms.
I knew that a fair-few open source licenses had been created, but how many, and how long have they been in use?
I don’t know of any other work in this area, and the fastest way to get lots of information on open source licenses was to scrape the brand leader’s licensing page, using the Wayback Machine to obtain historical data. Starting in mid-2007, the OSI licensing page kept to a fixed format, making automatic extraction possible (via an awk script); there were few pages archived for 2000, 2001, and 2002, and no pages available for 2003, 2004, or 2005 (if you have any OSI license lists for these years, please send me a copy).
What do I now know?
Over the years OSI have listed 110 different open source licenses, and currently lists 81. The actual number of license names listed, since 2000, is 205; the ‘extra’ licenses are the result of naming differences, such as the use of dashes, inclusion of a bracketed acronym (or not), license vs License, etc.
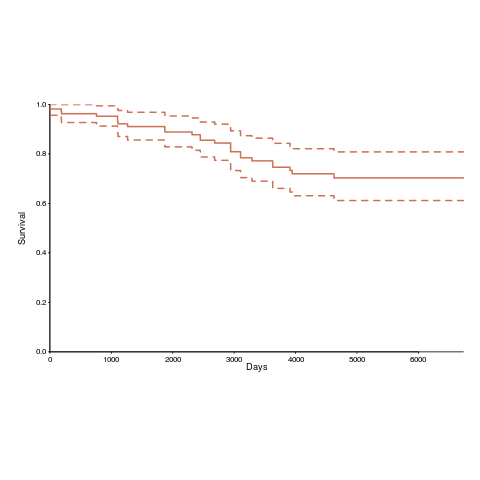
Below is the Kaplan-Meier survival curve (with 95% confidence intervals) of licenses listed on the OSI licensing page (code+data):
How many license proposals have been submitted for review, but not been approved by OSI?
Patrick Masson, from the OSI, kindly replied to my query on number of license submissions. OSI don’t maintain a count, and what counts as a submission might be difficult to determine (OSI recently changed the review process to give a definitive rejection; they have also started providing a monthly review status). If any reader is keen, there is an archive of mailing list discussions on license submissions; trawling these would make a good thesis project