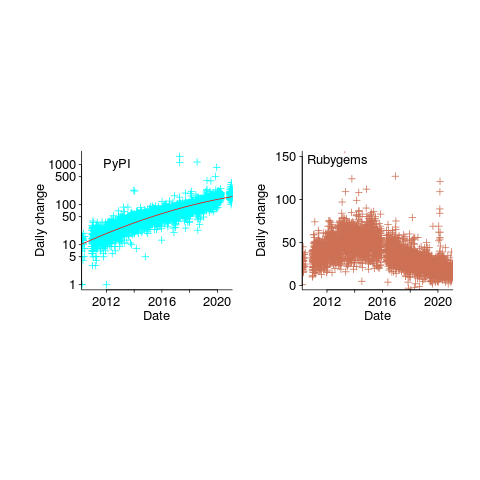Derek Jones from The Shape of Code
Programming languages are like pop groups in that they have followers, fans and supporters; new ones are constantly being created and some eventually become widely popular, while those that were once popular slowly fade away or mutate into something else.
Creating a language is a relatively popular activity. Science fiction and fantasy authors have been doing it since before computers existed, e.g., the Elf language Quenya devised by Tolkien, and in the computer age Star Trek’s Klingon. Some very good how-to books have been written on the subject.
As soon as computers became available, people started inventing programming languages.
What have been the major factors influencing the growth to widespread use of a new programming languages (I’m ignoring languages that become widespread within application niches)?
Cobol and Fortran became widely used because there was widespread implementation support for them across computer manufacturers, and they did not have to compete with any existing widely used languages. Various niches had one or more languages that were widely used in that niche, e.g., Algol 60 in academia.
To become widely used during the mainframe/minicomputer age, a new language first had to be ported to the major computers of the day, whose products sometimes supported multiple, incompatible operating systems. No new languages became widely used, in the sense of across computer vendors. Some new languages were widely used by developers, because they were available on IBM computers; for several decades a large percentage of developers used IBM computers. Based on job adverts, RPG was widely used, but PL/1 not so. The use of RPG declined with the decline of IBM.
The introduction of microcomputers (originally 8-bit, then 16, then 32, and finally 64-bit) opened up an opportunity for new languages to become widely used in that niche (which would eventually grow to be the primary computing platform of its day). This opportunity occurred because compiler vendors for the major languages of the day did not want to cannibalize their existing market (i.e., selling compilers for a lot more than the price of a microcomputer) by selling a much lower priced product on microcomputers.
BASIC became available on practically all microcomputers, or rather some dialect of BASIC that was incompatible with all the other dialects. The availability of BASIC on a vendor’s computer promoted sales of the hardware, and it was not worthwhile for the major vendors to create a version of BASIC that reduced portability costs; the profit was in games.
The dominance of the Microsoft/Intel partnership removed the high cost of porting to lots of platforms (by driving them out of business), but created a major new obstacle to the wide adoption of new languages: Developer choice. There had always been lots of new languages floating around, but people only got to see the subset that were available on the particular hardware they targeted. Once the cpu/OS (essentially) became a monoculture most new languages had to compete for developer attention in one ecosystem.
Pascal was in widespread use for a few years on micros (in the form of Turbo Pascal) and university computers (the source of Wirth’s ETH compiler was freely available for porting), but eventually C won developer mindshare and became the most widely used language. In the early 1990s C++ compiler sales took off, but many developers were writing C with a few C++ constructs scattered about the code (e.g., use of new, rather than malloc/free).
Next, the Internet took off, and opened up an opportunity for new languages to become dominant. This opportunity occurred because Internet related software was being made freely available, and established compiler vendors were not interested in making their products freely available.
There were people willing to invest in creating a good-enough implementation of the language they had invented, and giving it away for free. Luck, plus being in the right place at the right time resulted in PHP and Javascript becoming widely used. Network effects prevent any other language becoming widely used. Compatible dialects of PHP and Javascript may migrate widespread usage to quite different languages over time, e.g., Facebook’s Hack.
Java rode to popularity on the coat-tails of the Internet, and when it looked like security issues would reduce it to niche status, it became the vendor supported language for one of the major smart-phone OSs.
Next, smart-phones took off, but the availability of Open Source compilers closed the opportunity window for new languages to become dominant through lack of interest from existing compiler vendors. Smart-phone vendors wanted to quickly attract developers, which meant throwing their weight behind a language that many developers were already familiar with; Apple went with Objective-C (which evolved to Swift), Google with Java (which evolved to Kotlin, because of the Oracle lawsuit).
Where does Python fit in this grand scheme? I don’t yet have an answer, or is my world-view wrong to treat Python usage as being as widespread as C/C++/Java?
New programming languages continue to be implemented; I don’t see this ever stopping. Most don’t attract more users than their implementer, but a few become fashionable amongst the young, who are always looking to attach themselves to something new and shiny.
Will a new programming language ever again become widely used?
Like human languages, programming languages experience strong networking effects. Widely used languages continue to be widely used because many companies depend on code written in it, and many developers who can use it can obtain jobs; what company wants to risk using a new language only to find they cannot hire staff who know it, and there are not many people willing to invest in becoming fluent in a language with no immediate job prospects.
Today’s widely used programmings languages succeeded in a niche that eventually grew larger than all the other computing ecosystems. The Internet and smart-phones are used by everybody on the planet, there are no bigger ecosystems to provide new languages with a possible route to widespread use. To be widely used a language first has to become fashionable, but from now on, new programming languages that don’t evolve from (i.e., be compatible with) current widely used languages are very unlikely to migrate from fashionable to widely used.
It has always been possible for a proficient developer to dedicate a year+ of effort to create a new language implementation. Adding the polish need to make it production ready used to take much longer, but these days tool chains such as LLVM supply a lot of the heavy lifting. The problem for almost all language creators/implementers is community building; they are terrible at dealing with other developers.
It’s no surprise that nearly all the new languages that become fashionable originate with language creators who work for a company that happens to feel a need for a new language. Examples include:
- Go created by Google for internal use, and attracted an outside fan base. Company languages are not new, with IBM’s PL/1 being the poster child (or is there a more modern poster child). At the moment Go is a trendy language, and this feeds a supply of young developers willing to invest in learning it. Once the trendiness wears off, Google will start to have problems recruiting developers, the reason: Being labelled as a Go developer limits job prospects when few other companies use the language. Talk to a manager who has tried to recruit developers to work on applications written in Fortran, Pascal and other once-widely used languages (and even wannabe widely used languages, such as Ada),
- Rust a vanity project from Mozilla, which they have now abandoned. Did Rust become fashionable because it arrived at the right time to become the not-Google language? I await a PhD thesis on the topic of the rise and fall of Rust,
- Microsoft’s C# ceased being trendy some years ago. These days I don’t have much contact with developers working in the Microsoft ecosystem, so I don’t know anything about the state of the C# job market.
Every now and again a language creator has the social skills needed to start an active community. Zig caught my attention when I read that its creator, Andrew Kelley, had quit his job to work full-time on Zig. Two and a-half years later Zig has its own track at FOSEM’21.
Will Zig become the next fashionable language, as Rust/Go popularity fades? I’m rooting for Zig because of its name, there are relatively few languages whose name starts with Z; the start of the alphabet is over-represented with language names. It would be foolish to root for a language because of a belief that it has magical properties (e.g., powerful, readable, maintainable), but the young are foolish.


 , where
, where  is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all
is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all