Allan Kelly from Allan Kelly Associates
Building software is not like digging a hole in the ground: your target changes as you dig, the people and machines you use change the outcome as much as any original idea, and you never really know when to stop digging.
Years ago I was hired by Reuters to build an interface connector between the Liffe trading exchange and their data systems. Another developer started a few weeks after me. In the end we produced about half a dozen modules that worked together to make the connection. But we only produced that many because we were over staffed. In reality the one module I wrote handled 90% of the work required, the other modules were largely superfluous. And certainly the extra time which would have been required to make my module do 100% of the work was less than the time I spent to make sure it worked with the other.
Regular readers have probably already recognised Kelly’s Second Law of software: Inside every large development effort there is a small one struggling to get out
This itself is an example of Parkinson’s Law: work expands so as to fill the time available for its completion.
Actually you might restate my second law as Parkinson’s Law in reverse: constraining the capacity to do work reduces the amount of work to do. If you think about it this is a result of Conway’s Law: system designs copy the communication channels in the organization which creates the system.
Economists see a related phenomenon as the Lump of Work fallacy: people assume there is a fixed lump of work to do. If there are more people to do the work (say from immigration) then there will be unemployment – or possibly wages will be forced down and same work is distributed between more people. However it doesn’t national economies work like that, more people demand more food, houses, healthcare, schools and so on. What is true in the small is not true in the large. The net effect can be positive for countries but exactly how and by how much is hotly debated.
Software development has its own lump of work fallacy. There isn’t a fixed amount of work to do. Rather than saying “How many people will it take and how long will it take?” It is better to say “If we have five people working on this for three months what progress can we make?”
Writing software is not like digging a hole in the ground: the work to do is neither really known in advance nor is it fixed. Adding people actually increases the amount of work to do – Brooks’s Law.
At the start nobody really knows what it required, they may get lucky but more often that not once the thing is put in front of clients and (potential) customers the ask changes. I’ve heard this called Humphrey’s Law (after Watts Humphrey) although that name is not in common usage and there is another Humphrey’s Law from the world of psychology – which is connected with time estimation discussions for different reasons.
When you put Parkinson’s Law together with this “don’t know until I see it” law you get Hofstadter’s law: It always takes longer than you expect, even when you take into account Hofstadter’s Law.
Assume for the moment that one can know what is wanted in advance there is another problem: there are multiple ways to achieve the same result. There is no one true way in software development, there are always multiple ways to achieve the same end result.
Even if one was to fix the big questions – the OS, the delivery platform, the programming language and the database and so on – then you can still create very different implementations for the same thing. Or as I usually put it “there are many ways to dice the onion” – my Crown Jewels post describes how I can get wildly different time and money estimates for what is basically the same piece of work.
Of course the big consequence of these is estimation – how can anyone estimate in these circumstances? Let me go further and suggest that the process of estimating the work to do is more likely than not to increase the amount of work to do. Not only does estimation take time to do itself, but there when estimating there is a tendency to “play safe” and favour larger estimates even when these estimates are themselves underestimates (see Vierordt’s law.)
Sometimes it feels like quantum physics: when one parameter is measured another changes, we can know the speed but not the direction, or the direction but not the speed.
I’m not sure I have a complete answer but I have some of the pieces.
Start new work with a Minimally Viable Team: task the team to start immediately and in parallel work to understand what is needed and create potential solutions.
Keep teams stable: This contains a lot of variables and provides some past performance data to include in calculations. It will at times be necessary for the teams to call in more help – pull more skills and resources as needed.
By working with existing and minimally viable teams the problems are partially constrained: the technologies available are mostly the technologies the team knows already, the number of people available to work on the work is the number of people on the team. In time you may change both these parameters but initially they are constraints to work within.
Use active portfolio management and governance to kill work which is under performing or escalating beyond expectations.
The next time someone says “Building software should be like building a house” please remind them you aren’t building a house. What software engineers do is massively more variable and complex than building another example of the same thing.
Back at Reuters, the bright side was that the over engineered system we built wasn’t just used for Liffe, it was used to connect 2 or 3 other exchanges too so maybe over staffing was worth it. Except I don’t believe it really made economic sense, it would have been better to get the one exchange working and only add the minimum to the system when the second and third exchanges came along – diseconomies of scale again.
Subscribe to my blog and download Continuous Digital for free – normal price $9.99/£9.95/€9.95
The post Software is not a lump or work to do (and the laws which prove it) appeared first on Allan Kelly Associates.


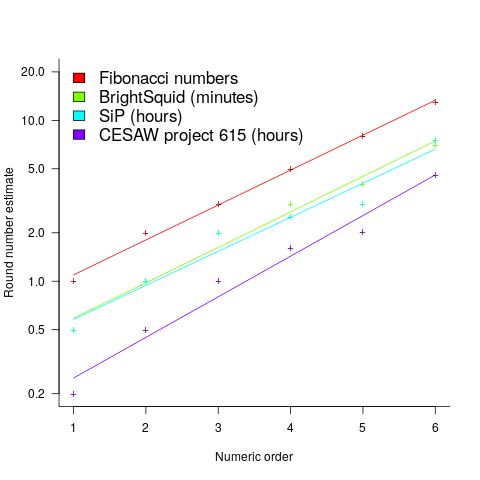
 (there is a small variation in the value of the constant; the smallest value for project 615 was probably calculated rather than being human selected).
(there is a small variation in the value of the constant; the smallest value for project 615 was probably calculated rather than being human selected). . I await the data needed to answer this question.
. I await the data needed to answer this question.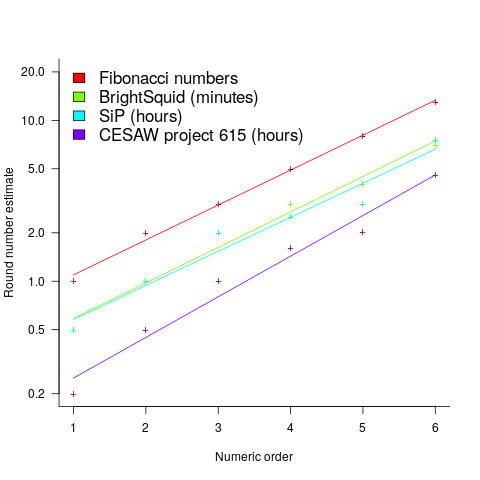
 (there is a small variation in the value of the constant; the smallest value for project 615 was probably calculated rather than being human selected).
(there is a small variation in the value of the constant; the smallest value for project 615 was probably calculated rather than being human selected). . I await the data needed to answer this question.
. I await the data needed to answer this question. , where
, where  is a constant that varies between projects, often explains around 50% of the variance present in the data. This equation shows that developers under-estimate short tasks and over-estimate long tasks. The exponent,
is a constant that varies between projects, often explains around 50% of the variance present in the data. This equation shows that developers under-estimate short tasks and over-estimate long tasks. The exponent,  , applies across most projects in the data,
, applies across most projects in the data,