Arne Mertz from arne-mertz.de
Now that we know good reasons to do code reviews, which parts of our code need to be reviewed? What does not need review? This post is part of a […]
The post Code Reviews – What? (Part 2) appeared first on .
Aggregating coding blogs
Arne Mertz from arne-mertz.de
Now that we know good reasons to do code reviews, which parts of our code need to be reviewed? What does not need review? This post is part of a […]
The post Code Reviews – What? (Part 2) appeared first on .
Derek Jones from The Shape of Code
Two things need to occur for a user to experience a fault in a program:
Data on the distribution of user input values is extremely rare, and we are left having to look for the shadows that the input distribution creates.
Csmith is a well-known tool for generating random C source code. I spotted an interesting plot in a compiler fuzzing paper and Yang Chen kindly sent me a copy of the data. In compiler fuzzing, source code is automatically generated and fed to the compiler, various techniques are used to figure out when the compiler gets things wrong.
The plot below is a count of the number of times each fault in gcc has been triggered (code+data). Multiple occurrences of the same fault are experienced because the necessary input values occur multiple times in the generated source code (usually in different files).
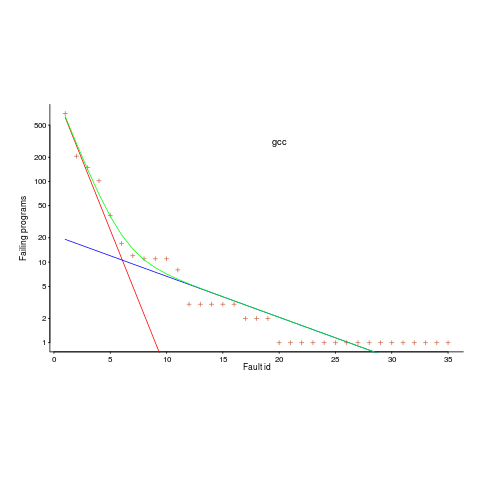
The green line is a fitted regression model, it’s a bi-exponential, i.e., the sum of two exponentials (the straight lines in red and blue).
The obvious explanation for this bi-exponential behavior (explanations invented after seeing the data can have the flavor of just-so stories, which is patently not true here  is that one exponential is driven by the presence of faults in the code and the other exponential is driven by the way in which Csmith meanders over the possible C source.
is that one exponential is driven by the presence of faults in the code and the other exponential is driven by the way in which Csmith meanders over the possible C source.
So, which exponential is generated by the faults and which by Csmith? I’m still trying to figure this out; suggestions welcome, along with alternative explanations.
Is the same pattern seen in duplicates of user reported faults? It does in the small amount of data I have; more data welcome.
Arne Mertz from arne-mertz.de
Are you doing code reviews with your current team? Do you feel they help a lot or are they just a waste of time? In part 1 of this blog […]
The post Code Reviews – Why? (Part 1) appeared first on .
Products, the Universe and Everything from Products, the Universe and Everything
Visual Lint 6.0.7.289 is now available. This is a recommended maintenance update for Visual Lint 6.0, and includes the following changes:Chris Oldwood from The OldWood Thing
The first indication that we seemed to have a problem was when some of the background processing jobs failed. The support team naturally looked at the log files where the jobs had failed and discovered that the cause was an inability to log-in to the database during process start-up. Naturally they tried to log-in themselves using SQL Server Management Studio or run a simple “SELECT GetDate();†style query via SQLCMD and discovered a similar problem.
Initial Symptoms
With the database appearing to be up the spout they raised a priority 1 ticket with the DBA team to investigate further. Whilst this was going on I started digging around the grid computation services we had built to see if any more light could be shed on what might be happening. This being the Windows Server 2003 era I had to either RDP onto a remote desktop or use PSEXEC to execute remote commands against our app servers. What surprised me was that these were behaving very erratically too.
This now started to look like some kind of network issue and so a ticket was raised with the infrastructure team to find out if they knew what was going on. In the meantime the DBAs came back and said they couldn’t find anything particularly wrong with the database, although the transaction log consumption was much higher than usual at this point.
Closing In
Eventually I managed to remote onto our central logging service [1] and found that the day’s log file was massive by comparison and eating up disk space fast. TAILing the central log file I discovered page upon page of the same error about some internal calculation that had failed on the compute nodes. At this point it was clearly time to pull the emergency chord and shut the whole thing down as no progress was being made for the business and very little in diagnosing the root of the problem.
With the tap now turned off I was able to easily jump onto a compute node and inspect its log. What I discovered there was every Monte Carlo simulation of every trade it was trying to value was failing immediately in some set-up calculation. The “best efforts†error handling approach meant that the error was simply logged and the valuation continued for the remaining simulations – rinse and repeat.
Errors at Scale
Of course what compounded the problem was the fact that there were approaching 100 compute nodes all sending any non-diagnostic log messages, i.e. all warnings and errors, across the network to one central service. This service would in turn log any error level messages in the database’s “error log†table.
Consequently with each compute node failing rapidly (see “Black Hole - The Fail Fast Anti-Patternâ€) and flooding the network with thousands of log messages per-second the network eventually became saturated. Those processes which had long-lived network connections (we used a high-performance messaging product for IPC) would continue to receive and generate traffic, albeit slowly, but establishing new connections usually resulted in some form of timeout being hit instead.
The root cause of the compute node set-up calculation failure was later traced back to some bad data which itself had resulted from poor error handling in some earlier initial batch-level calculation.
Points of Failure
This all happened just before Michael Nygard published his excellent book Release It! Some months later when I finally read it I found myself frequently nodding my head as his tales of woe echoed my own experiences.
One of the patterns he talks about in his book is the use of bulkheads to stop failures “jumping the cracksâ€. On the compute nodes the poor error handling strategy meant that the same error occurred over-and-over needlessly instead of failing once. The use of a circuit breaker could also have mitigated the volume of errors generated and triggered some kind of cooling off period.
Duplicating the operational log data in the same database as the business data might have been a sane thing to do when the system was tiny and handling manual requests, but as the system became more automated and scaled out this kind of data should have been moved elsewhere where it could be used more effectively.
One of the characteristics of a system like this is that there are a lot of calculations forming a pipeline, so garbage-in, garbage-out means something might not go pop right away but sometime later when the error has compounded. In this instance an error return value of –1 was persisted as if it was normal data instead of being detected. Latter stages could do sanity checks on data to avoid poisoning the whole thing before it’s too late. It should also have been fairly easy to run a dummy calculation on the core inputs before opening the flood gates to mitigate a catastrophic failure, at least, for one due to bad input data.
Aside from the impedance mismatch in the error handling of different components there was also a disconnect in the error handling in the code that was biased towards one-off trader and support calculations, where the user is present, versus batch processing where the intention is for the system to run unattended. The design of the system needs to take both needs into consideration and adjust the error handling policy as appropriate. (See “The Generation, Management and Handling of Errors†for further ideas.)
Although the system had a monitoring page it only showed the progress of the entire batch – you needed to know the normal processing speed to realise something was up. A dashboard needs a variety of different indicators to show elevated error rates and other anomalous behaviour, ideally with automatic alerting when the things start heading south. Before you can do that though you need the data to work from, see “Instrument Everything You Can Afford Toâ€.
The Devil is in the (Non-Functional) Details
Following Gall’s Law to the letter this particular system had grown over many, many years from a simple ad-hoc calculation tool to a full-blown grid-based compute engine. In the meantime some areas around stability and reliably had been addressed but ultimately the focus was generally on adding support for more calculation types rather than operational stability. The non-functional requirements are always the hardest to get buy-in for on an internal system but without them it can all come crashing down and end in tears with some dodgy inputs.
[1] Yes, back then everyone built their own logging libraries and tools like Splunk.
Simon Brand from Simon Brand
Last week I released an article entitled “Functional exceptionless error-handling with optional and expectedâ€. The idea was to talk about some good ways to handle errors for those cases where you don’t want to use exceptions, but without starting a huge argument about whether exceptions are good or bad. That post has since spawned arguments about exceptions on Hacker News, two other blog posts, and three Reddit threads. Ten points for effort, zero for execution. Since the argument has now started, I feel inclined to give my own view on the matter.
I know people who think exceptions are dangerous. I don’t personally know anyone who thinks ADT-based error handling is dangerous, but I’m sure the Internet is full of them. What I think is dangerous is cargo cult software engineering. Many people take a stance on either side of this divide for good reasons based on the constraints of their platform, but an unfortunately large number just hear a respected games programmer say “exceptions are evil!â€, believe that this applies to all cases and assert it unconditionally. How do we fight this? With data.
I believe that as a community we need to be able to answer these questions:
I have an intuition about all of these, backed by some understanding of the actual code which is generated and how it performs, as I’m sure many of you do. But we hit a problem when it comes to teaching. I don’t believe that teaching an intuition can build an intuition. Such a thing can only be built by experimentation or the reduction of hard data into a broad understanding of what that data points towards. If we answer all of questions above with hard data, then we can come up with a set of strong, measurable guidelines for when to use different kinds of error handling, and we can have something concrete to point people towards to help build that intuition. The C++ Core Guidelines provides the former, but not the latter. Furthermore, when I talk about “hard dataâ€, I don’t just mean microbenchmarks. Microbenchmarks can help, sure, but writing them such that they have the realistic error patterns, cache behaviour, branch prediction, etc. is hard.
Of course, many people have tried to answer these questions already, so I’ve teamed up with Matt Dziubinski to put together a set of existing resources on error handling. Use it to educate yourselves and others, and please submit issues/pull requests to make it better. But I believe that there’s still work to be done, so if you’re a prospective PhD or Masters student and you’re looking for a topic, consider helping out the industry by researching the real costs of different error handling techniques in realistic code bases with modern compilers and modern hardware.
throw end_of_blog_post;
Chris Oldwood from The OldWood Thing
I’ve generally been pretty fortunate with the people I’ve found myself working with. For the most part they’ve all been continuous learners and there has always been some give and take on both sides so that we’ve learned different things from each other. Many years ago on one particular contract I had the misfortune to be thrown a curveball twice, by two different teammates. This post is a reflection on both theirs and my behaviour.
The Unsolicited Review
The first incident occurred when I had only been working on the project for a few weeks. Whilst adding some new behaviour to one of the support command-line tools I spotted some C++ code similar to this:
std::vector<string*> hosts;
for (. . .)
hosts.push_back(new string(. . .));
Having been used to using values, the RAII idiom and smart pointers for so long in C++ I was genuinely surprised by it. Naturally I flicked back through the commit log to see who wrote it and whether they could shed any light on it. This was also out of place given the rest of the code I’d seen. I discovered not only who the author was, but realised they were sitting but a few feet away and so decided to tap them up if they weren’t busy to find out a little more.
Although I cannot be sure, I believe that I approached them in a friendly manner and enquired why this particular piece of code used raw pointers instead of one of the more usual resource management techniques [1]. What I expected was the usual kind of “Doh!†reply that we often give when we noticed we’ve done something silly. What I absolutely wasn’t prepared for was the look of anger on their face followed by them barking “Are you reviewing my code? Have I asked you to do that?â€
In somewhat of a daze I apologised for interrupting them and left the code as-was for the time being until I had due cause to fix it – I didn’t want to be seen to be going behind someone’s back either at this point as that might only cause even more friction.
Not long after this episode I had to work more closely with them on the build and deployment scripts. They would make code changes but then make no effort to test them, so even when I knew they were wrong I felt I should wait for the build to fail (a 2 hour process!) rather than be seen to “review†it.
Luckily the person left soon after, but I had already been given the remit to fix as many memory leaks as possible so could close out my original issue before that point.
Whose Bug?
The second incident features someone I actually referred to very briefly in a post over 5 years ago (“Can Code Be Too Simple?â€), but that was for a different reason a little while after the following one.
I got pulled into a support conversation after some compute nodes appeared to be failing to load the cache file for a newly developed cache mechanism. For some reason the cache file appeared to be corrupted and so every time the compute process started, it choked on loading it. The file was copied from a UNC share on-demand and so the assumption was that this was when the corruption was happening.
What I quickly discovered was that the focus of the investigation was around the Windows API call CopyFile(). The hypothesis was that there was a bug in this function which was causing the file to become truncated.
Personally I found this hypothesis somewhat curious. I suggested to the author that the chances of there being a bug in such a core Windows API call in a version of Windows Server that was five years old was incredibly slim – not impossible of course, but highly unlikely. Their response was that “my code works†and therefore the bug must be in the Windows call. Try as I might to get them to entertain other possibilities and to investigate other avenues – that our code elsewhere might have a problem – they simply refused to accept it.
Feeling their analysis was somewhat lacklustre I took a look at the log files myself for both the compute and nanny processes and quickly discovered the source of the corruption. (The network contention copying the file was causing it to exceed the process start-up timeout and it was getting killed by the nanny during the lengthy CopyFile() call [2].)
Even when I showed them the log messages which backed up my own hypothesis they were still somewhat unconvinced until the fix went in and the problem went away.
Failure is Always an Option
Although I hadn’t heard it back then, this quote from Jeffrey Snover really sums up the attitude I’ve always tried to adopt with my team mates:
“When confronted by conflict respond with curiosity.â€
Hence whenever someone has found a fault in my code or I might have done the same with theirs I do not just assume I’m right. In the first example I was 99% sure I knew how to fix the code but that wasn’t enough, I wanted to know if I was missing something I didn’t know about C++ or the codebase, or if the same was true for the author. In short I wanted to fix the root cause not just the symptoms.
In the second example there was clearly a conflict in our approaches. I’m willing to accept that any bug is almost certainly of my own making and that I’ll spend as much time as possible working on that basis until the only option left is it for to be in someone else’s code. Although I was okay to entertain their hypothesis, I also wanted to understand why they felt so sure of their own work as Windows API bugs are, in my experience, pretty rare and well documented [3].
Everyone has their off days and I’m no exception. If these had been one of those I’d not be writing about them. On the contrary these were just the beginning of some further unfortunate experiences. Both people continued to display tendencies that showed they were overconfident in their approach whilst also making it difficult for anyone else to critique their work. For (supposedly) experienced professionals I would have expected a little more personal reflection and openness.
The consequence of being such a closed book is that it is hard for others who may be able to provide valuable insights and learning to want to do so. When you work with people who are naturally reflective and inquisitive you get a buzz from helping them grow, and likewise when they teach you something new in return. With junior programmers you can allow for a certain amount of arrogance [4] and that’s a challenge worth taking on, but with much older programmers the view that “an old dog can’t learn new tricks†makes the prospect far less rewarding.
As an “old dog†myself I know that I probably have to work a little harder these days to appear open and attentive to change and I believe that process starts by accepting I’m far from infallible.
[1] In this instance simply using string values directly was more than adequate.
[2] The immediate fix of course was simply to copy to a temporary filename and then rename on completion, see “Copy & Rename (Like Copy & Swap But For File-Systems)â€.
[3] The “Intriguing SCHTASKS Bug†that I found back in 2011 was certainly unusual, but a little googling turned up an answer reasonably quickly.
[4] See “The Downs and Ups of Being an ACCU Member†for my own watershed moment about how high the bar really goes.
a.k. from thus spake a.k.
Array.slice does, we first implemented ak.partition which divides elements into two ranges; those elements that satisfy some given condition followed by those elements that don't. We saw how this could be used to implement the quicksort algorithm but instead defined ak.sort to sort a range of elements using Array.sort, slicing them out beforehand and splicing them back in again afterwards if they didn't represent whole arrays. We did use it, however, to implement ak.nthElement which puts a the correctly sorted element in a given position position within a range, putting before it elements that are no greater and after it elements that are no smaller. Finally, we implemented ak.partialSort which puts every element in a range up to, but not including, a given position into its correctly sorted place with all of the elements from that position onwards comparing no less than the last correctly sorted element.